1 前言:为什么写这本书
和Rust结缘是2019年,当时为了能看懂libra的源码,开始了Rust的学习。起初的目标只是能看懂Rust的代码就好,谁知一看竟然发现这门编程语言很对我的胃口,于是开启了真正的Rust学习之路。彼时的工作中并没有使用Rust,但是周围的小伙伴有在研究谷歌操作系统fuchsia,跟他们的交流更加坚定了我要学习这门编程语言的想法。
所谓“拳不离手,曲不离口”,要能熟练地掌握一门编程语言必须要有大量的练习,但是因为在工作中并不会使用Rust,这无疑会让Rust学习的效果打折扣。为了促使自己不断地学习输入,我想到了边学习边录制视频,然后将视频放到B站上。虽然当时对Rust的理解不够深入,甚至是有些视频中还有错误,但还是让我有了一批一起学习Rust的粉丝。
2021年换工作后算是真正开始使用Rust了,在真正使用Rust的过程中也曾产生过撰写一本Rust教程的想法。但是一直感觉写书是一件严肃的事情,更何况自己的Rust水平也只能算是个熟练的使用者而已。直到最近和DaviRain聊天,说起如果能有办法降低一点点Rust入门的难度,也算是给Rust做了一点贡献,于是决定和DaviRain写这本书。
所以本书定位就是为了方便入门Rust,在本书中:
- 对于Rust中相对简单的语法就是简单地描述,然后给出示例。
- 对于一些复杂的、不太好理解的,我们觉得不属于入门需要掌握的知识,就尽量少提及或者不提及。
- 尽量多地画图,例如对Rust的内存模型、所有权等尽量多地画图描述。
本书撰写过程中,我们参考了其它的Rust书籍,参考的书籍主要有《The Rust Programming Language》、《Rust语言圣经》、《Rust入门秘籍》、《Rust第一课》等。本书第2.1节(为什么选择Rust)是由ChatGPT4进行生成;第3.8节复合数据类型、第3.15节常见的Collections、第4章Rust使用技巧由DaviRain完成;第3.9节Trait部分由DaviRain和令狐壹冲一起完成;其它章节由令狐壹冲完成。但是由于我们自身水平的问题,本书必然存在一些错误和描述不清楚的地方,希望各位读者能够不吝指正!
愿本书能让您的Rust入门之路变得不再崎岖!
令狐壹冲
本书的其它贡献者
本书在上线后,有一些朋友对本书提了些建议,他们是: @tk103331 @geometryolife 群友 云南青山 @daleydeng
2 欢迎来到Rust的世界
2.1 为什么选择Rust
2.1.1 Rust的历史与背景
Rust是一种现代的系统编程语言,它注重性能、安全性和并发。Rust最初由Mozilla研究院的Graydon Hoare于2006年开始设计,最早的目标是为了解决C++在系统编程领域的一些痛点。在2010年,Mozilla正式开始支持这个项目,从那时起,Rust开始迅速发展并逐渐成为一个强大的编程语言。
1. 设计理念
Rust的设计理念是将系统编程的性能与安全性相结合。它的核心创新是引入了一套所有权系统,这套系统能在编译时检测许多常见的内存错误,如空指针解引用、数据竞争等。这种设计使得Rust在保持C和C++级别性能的同时,提供了更高的内存安全性。
2. 发展历程
- 2006年:Graydon Hoare开始设计Rust。
- 2009年:Mozilla开始关注Rust,希望它能成为一种更安全的系统编程语言。
- 2010年:Mozilla正式支持Rust项目。
- 2012年:Rust的第一个编译器(rustc)实现了自举(即用Rust编写的编译器可以编译自己)。
- 2014年:Rust 0.9版本发布,从此Rust开始逐渐稳定。
- 2015年:Rust 1.0正式发布,稳定版本的Rust开始对外提供支持。
- 2016年:Rust开始获得广泛关注,社区逐渐壮大。
- 2018年:WebAssembly的推广使得Rust成为一个受欢迎的前端编程语言。
3. 社区与生态系统
随着Rust的发展,其社区和生态系统也在不断壮大。Rust编程语言被广泛应用于各种领域,如网络编程、游戏开发、操作系统、嵌入式系统、区块链等。此外,Rust已经连续多年被Stack Overflow开发者调查评为最受欢迎的编程语言。
Rust的成功和流行归功于其活跃的社区和丰富的第三方库。社区不断努力改进和扩展Rust的功能,使其成为一个更加实用和强大的编程语言。总的来说,Rust的历史与背景显示了Rust是一个充满创新、活力和潜力的编程语言,它将继续为现代软件开发带来更多的机会。
2.1.2 Rust的主要优势
Rust的设计目标是为程序员提供一种高性能、安全且具有现代化特性的系统编程语言。以下是Rust的一些主要优势:
1. 内存安全性
Rust通过其独特的所有权系统、生命周期和借用检查器确保了内存安全。这些功能让Rust能够在编译时检测许多常见的内存错误,如悬垂指针、空指针解引用、数据竞争等。这种设计减少了内存泄漏、悬垂指针等问题的出现,从而使得编写安全的代码变得更加容易。
2. 高性能
Rust注重零开销抽象(zero-cost abstractions),这意味着Rust提供的高级抽象不会对程序性能产生负面影响。Rust的性能与C和C++相当,这使得它成为一个理想的选择,尤其是对于对性能要求较高的系统编程任务。
3. 并发友好
Rust的内存模型和类型系统让并发变得更加简单和安全。通过提供原子操作和线程安全的数据结构,Rust在编译时就可以预防数据竞争等多线程问题。这使得Rust在多核处理器和分布式系统领域具有优势。
4. 易于集成
Rust的C兼容的FFI(Foreign Function Interface)允许轻松地与其他编程语言集成。这使得Rust可以逐步替换现有的C和C++代码,提高系统的安全性和性能,而无需重写整个项目。
5. 生产力与现代化特性
Rust提供了许多现代编程语言的特性,如模式匹配、类型推断、闭包等。这些特性可以提高程序员的生产力,使得编写代码更加愉快。Rust的丰富的标准库和第三方库也使得开发者能够轻松地找到所需的功能。
6. 活跃的社区与生态系统
Rust拥有一个友好、活跃且不断壮大的社区。开发者们分享知识、讨论问题、改进编译器和标准库,这使得Rust不断进化和完善。Rust生态系统的成熟也使得开发者能够更容易地找到和使用高质量的第三方库。
总之,Rust的主要优势在于其内存安全性、高性能、并发友好、易于集成、生产力以及活跃的社区和生态系统。这些优势使得Rust成为一个非常有吸引力的编程语言,尤其适用于需要确保稳定性、安全性和高性能的系统。
随着Rust的普及和发展,越来越多的公司和开发者选择使用Rust来构建他们的项目。大型公司如Mozilla、Microsoft、Google、Amazon和Facebook等都在部分项目中采用了Rust。另外,Rust也在许多新兴领域和开源项目中得到了广泛的应用,例如:
- 网络编程:通过使用Tokio、Hyper等库,Rust可以构建高性能、可靠的网络应用和服务。
- WebAssembly:Rust是一个受欢迎的WebAssembly开发语言,可以构建快速、安全的前端应用。
- 游戏开发:Rust的高性能和内存安全性使其成为游戏开发的理想选择,Amethyst和Bevy等游戏引擎为开发者提供了丰富的功能。
- 嵌入式系统:Rust的高性能、低内存占用和安全性特性使其在嵌入式系统和物联网领域具有优势。
- 操作系统:Rust被用于开发一些创新的操作系统项目,如Redox OS和Tock OS等。
- 区块链技术:Rust在一些区块链项目中得到了应用,如Parity和Solana等。
因此,Rust的主要优势使其在许多领域都具有竞争力,为开发者提供了一个安全、高性能且具有现代化特性的编程工具。Rust的广泛应用和不断壮大的社区证明了其作为一种优秀的编程语言的价值。
2.1.3 Rust在不同领域的应用
Rust的高性能、内存安全和现代化特性使其在许多领域具有广泛的应用。以下是一些Rust在不同领域中的典型应用:
1. 网络编程
在网络编程领域,Rust的性能和安全性特性使其成为构建可靠、高性能服务器和网络应用的理想选择。例如,Tokio是一个使用Rust编写的高性能异步运行时,它可以让开发者轻松地构建高吞吐量、低延迟的服务。同时,Hyper是一个快速的HTTP库,可以用于构建网络客户端和服务器。
2. WebAssembly
Rust在WebAssembly开发中具有很大的优势。由于其性能和安全性,Rust成为了一个受欢迎的WebAssembly目标语言。通过将Rust编译为WebAssembly,开发者可以构建高性能、安全的前端应用程序,提高网页的加载速度和运行效率。
3. 游戏开发
Rust在游戏开发领域具有很大的潜力。其高性能和内存安全性特性使得Rust成为游戏开发的理想选择。Amethyst和Bevy是两个使用Rust编写的游戏引擎,它们为开发者提供了丰富的功能和性能优势。同时,Rust也可以与现有的游戏引擎(如Unity和Unreal Engine)进行集成,提供更安全的原生插件和后端服务。
4. 嵌入式系统和物联网
Rust在嵌入式系统和物联网领域具有优势。由于其高性能、低内存占用和安全性特性,Rust成为了嵌入式设备开发的理想选择。使用Rust可以更容易地构建可靠、安全的嵌入式系统。此外,Rust在实时操作系统(RTOS)如Tock OS等项目中也得到了应用。
5. 操作系统开发
Rust在操作系统开发中具有很大的潜力。其内存安全和高性能特性使得Rust成为开发创新操作系统的理想选择。例如,Redox OS是一个使用Rust编写的现代化、安全的微内核操作系统。
6. 区块链技术
在区块链领域,Rust的高性能和安全性特性使其成为构建区块链系统的理想选择。一些知名的区块链项目,如Parity和Solana,都采用了Rust来实现其核心组件。这些项目展示了Rust在处理高并发、安全性要求高的场景中的能力。
7. 机器学习和数据科学
虽然Python在机器学习和数据科学领域占据主导地位,但Rust也在逐渐成为一个有吸引力的选择。Rust的高性能特性使其在计算密集型任务中具有优势。ArrayFire-rust和ndarray等库提供了高性能的数组计算和线性代数功能,而tch-rs等库则提供了Rust的Torch绑定,允许在Rust中使用深度学习功能。
8. 跨平台开发
Rust具有良好的跨平台支持,可以轻松地在不同的操作系统和硬件架构上运行。这使得Rust成为构建跨平台应用的理想选择。例如,使用Rust编写的GUI库(如druid和iced)可以帮助开发者轻松地构建跨平台的桌面应用。
9. 系统工具与实用程序
Rust在系统工具和实用程序开发中也表现出色。Rust编写的工具可以在性能、安全性和可维护性方面取得优异的表现。例如,ripgrep是一个使用Rust编写的高性能grep工具,它在速度和功能上超越了许多现有的grep实现。
10. Web开发
虽然Rust主要用于系统编程,但它也在Web开发领域取得了一定的成功。使用Rocket、Actix Web和Tide等Web框架,开发者可以用Rust构建高性能、安全的Web应用程序和API服务。
综上所述,Rust在不同领域的应用表明了它作为一种通用编程语言的潜力。随着Rust社区和生态系统的不断壮大,Rust将继续在各个领域发挥越来越重要的作用。
2.2 安装和配置Rust
2.2.1 安装Rust
1. 对于macOS和Linux用户
通过如下命令进行安装:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
2. 对于Windows用户
- 访问https://rustup.rs/ ,点击"Get started"。
- 下载
rustup-init.exe安装程序。 - 双击
rustup-init.exe运行安装程序,按照提示操作。 - 在安装过程中,选择默认选项(按回车键)即可。
- 安装完成后,重启计算机。
特别说明:在本书中,后续的所有的示例都在Ubuntu上进行。
2.2.2 验证安装
安装完成后,可以输入如下命令验证安装:
rustc --version
2.3 第一个Rust程序
本节将编写和运行本书的第一个Rust程序:hello_world
2.3.1 创建一个新的Rust项目
Rust使用Cargo作为官方的构建工具和包管理器,下面通过Cargo创建一个新的Rust项目:
cargo new hello_world
创建后,可以看到整个目录的结构如下:
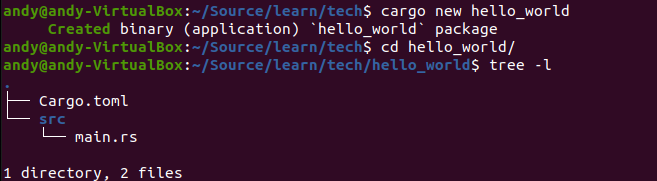
其中Cargo.toml是项目的配置文件,src为源代码目录,main.rs为主程序文件。
2.3.2 编写程序
默认情况下,main.rs文件中已经包含了一个简单的hello_world程序,代码如下:
fn main() { println!("Hello, world!"); }
其中,main函数是Rust程序的入口;而println!则是一个Rust宏(而非函数),用于在标准输出上打印一行文本。
2.3.3 编译并运行Hello, World程序
运行程序需要进去到项目目录中,然后运行cargo run命令即可,步骤如下:
cd hello_world
cargo run
运行结果如下:

2.3.4 理解Rust源码的基本结构
下面简单介绍Rust源码的结构。
1. main函数
main函数是程序的入口。当运行程序时,main函数将首先被调用。Rust中函数的定义以关键字fn开始,后跟函数名和参数列表,函数体则由一对花括号包围。main函数没有参数,也没有返回值。
2. println!宏
println!是一个用于向控制台输出一行文本的Rust宏。在例子中,我们向println!宏传递了一个字符串字面量"Hello, World!"作为参数。println!宏会将这个字符串作为控制台的输出。
3.1 变量和可变性
3.1.1 绑定
在Rust中,将值和变量关联的过程称为绑定,变量的绑定可以使用let关键字,如下:
#![allow(unused)] fn main() { let a = 1; // 将1绑定到变量a let mut b = 2; // 将2绑定到变量b let some_number = Some(2); // 将Some(2)绑定到some_number }
3.1.2 变量
Rust中变量分为不可变变量和可变变量。不可变变量不能对其进行二次绑定,可变变量可以对其进行二次绑定。
-
不可变变量定义方式如下:
#![allow(unused)] fn main() { let a: u32 = 1; // 将1绑定到a这个变量 let b = 0u32; let c = 1; // 定义时不指定类型,可以自动类型推导 }对不可变变量二次绑定一个值会报错:
#![allow(unused)] fn main() { let a: u32 = 1; // 将1绑定到变量a,a为不可变变量, a = 2; // 编译错误,a是不可变的变量,不能进行二次绑定 } -
可变变量定义方式如下:
#![allow(unused)] fn main() { let mut a: u32 = 1; // 通过mut关键字定义可变变量 a = 2; // 将2绑定到变量a,编译正确,因为a是可变变量,可以进行二次绑定 let mut b = 2; b = 3; }
设计思考: 从编译器的角度,如果一个值定义为不可变变量,那它就不会改变,更易于推导。想一下如果代码非常多,如果变量不会变化,但是允许它可变,其实会更容易滋生bug。
3.1.3 常量
常量是绑定到一个名称不允许改变的值,定义方式如下:
#![allow(unused)] fn main() { const HOUR_IN_SECONDS: u32 = 60 * 60; }
常量和不可变变量的区别:
-
不允许对常量使用
mut关键字,它总是不可变的,定义时必须显式地标注类型;#![allow(unused)] fn main() { let a = 1u32; // 编译正确 let a = 1; // 编译正确 const A: u32 = 1; // 编译正确 const B = 2u32; // 编译错误 const C = 2; // 编译错误 } -
常量可以在任何作用域声明,包括全局作用域;
-
常量只能被设置为常量表达式,不能是在运行时计算出来的值。
#![allow(unused)] fn main() { let a: u32 = 1; let b: u32 = 2; const A: u32 = a + b; // 编译错误 }
3.1.4 隐藏
Rust中可以定义一个与之前的变量同名的变量,这称之为第一个变量被第二个变量隐藏。隐藏和mut的区别:隐藏是定义了一个新的变量,而使用mut是修改原来的变量。
fn main() { let a: u32 = 1; // 这个变量a被下面的a隐藏掉了 let a: u32 = 2; // 定义了一个新的变量,这个变量也叫作a println!("a: {:?}", a); // 输出结果为2 let mut b: u32 = 1; // 定义可变变量b b = 2; // 对b的值进行的修改 println!("b: {:?}", b); // 输出结果为2 let c = 5; { // 在当前的花括号作用域内,对之前的c进行隐藏 let c = 3; println!("c: {:?}", c); // 输出结果为3 } println!("c: {:?}", c); // 输出结果为5 }
3.2 基本数据类型
Rust是静态类型语言,编译时就必须知道所有变量的类型。根据值以及其使用方式,Rust编译器通常能自动推导出变量的类型。Rust有两种数据类型子集,分别是:标量(scalar)类型和复合(compound)类型。
3.2.1 标量类型
标量类型包括:整型、浮点型、布尔类型和字符类型。
1. 整型和浮点型
Rust中的整型和浮点型如下:
| 长度 | 有符号 | 无符号 | 浮点型 |
|---|---|---|---|
| 8 bit | i8 | u8 | |
| 16 bit | i16 | u16 | |
| 32 bit | i32 | u32 | f32 |
| 64 bit | i64 | u64 | f64 |
| 128 bit | i128 | u128 | |
| arch | isize | usize |
说明:isize和usize的长度是和平台相关,如果CPU是32位的,则这两个类型是32位的,如果CPU是64位的,则这两个类型是64位的。
上面的表格中,f32和f64为浮点型,其它为整型。浮点型和整型一起构成数值类型。
(1)可以在数值字面量后面加上类型表示该数值的类型,如下:
fn main(){ let _a = 33u32; // 直接加类型后缀 let _b = 33_i32; // 使用_分隔数值和类型 let _c = 33_isize; let _d = 33_f32; }
(2)可以在数值的任意位置使用下划线分割来增强可读性,如下:
fn main(){ let _a = 10_000_000u32; let _b = 1_234_3_u32; let _c = 1_33_333f32; }
(3)当既不明确指定变量的类型,也不明确指定数值字面量的类型后缀时,Rust默认将整数当做i32类型,将浮点数当做f64类型,如下:
fn main(){ let _a = 33; // 等价于 let _a: i32 = 33; 等价于 let _a = 33i32; let _b = 64.123; // 等价于 let _b: f64 = 64.123; 等价于 let _b = 64.123f64; }
(4)Rust使用0b表示二进制、0o表示八进制、0x表示十六进制,如下:
fn main(){ let a: u32 = 0b101; // 二进制整数 let b: i32 = 0o17; // 八进制整数 let c: u8 = 1; // 十进制 let d: i32 = 0xac; // 十六进制整数 println!("{}, {}, {}, {}", a, b, c, d); // 5, 15, 1, 172 }
(5)Rust中所有的数值类型都支持基本数学运算:加、减、乘、除、取余,如下:
fn main() { let sum = 5 + 10; let difference = 95.5 - 4.3; let product = 4 * 30; let quotient = 56.7 / 32.2; let truncated = -5 / 3; // 结果为 -1 let remainder = 43 % 5; }
2. 布尔型
Rust中的布尔型用bool表示,有两个可能的值,为true和false。布尔类型使用的场景主要是条件表达式(控制流的内容),使用如下:
fn main() { // 定义方式 let a: bool = true; let b: bool = false; // 使用场景 if a { println!("a is true"); } else { println!("a is false"); } if b { println!("b is true"); } else { println!("b is false"); } }
3. 字符类型
Rust用char表示字符类型,用于存放单个unicode字符,占用4个字节空间。当存储char类型数据时,Rust会将其转换为utf-8编码的数据存储。char字面量是单引号包裹的任意单个字符,字符类型使用示例如下:
fn main() { let c: char = 'z'; let x: char = 'x'; let heart_eyed_cat: char = '😻'; }
3.2.2 原生复合类型
复合类型是将多个值组合成一个类型。Rust有两个原生复合类型:元组和数组。
1. 元组
圆括号以及其中逗号分割的值列表组成元组,定义一个元组方式如下:
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
可以将元组重新解构到变量上,如下:
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; // 接下来你可以使用x、y、z }
也可以直接使用元组的元素,如下:
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let first = x.0; let second = x.1; let third = x.2; }
不带任何值的元组,称为unit类型(单元元组),可以代表空值或者空的返回类型,如下:
fn main() { let x: () = (); // 将值()保存到类型为()的变量x中 }
2. 数组
数组中的每个元素的类型必须相同,数组的长度是固定的,数组的定义方式如下:
fn main() { let a = [1, 2, 3, 4, 5]; // 直接写数组的值 let b: [i32; 5] = [1, 2, 3, 4, 5]; // 显示指定数组的类型和长度 let c: [i32; 5] = [3; 5]; // 数组每个元素为同样的值,等价于 let a = [3, 3, 3, 3, 3]; }
数组通过索引来访问元素,索引从0开始计数,如下:
fn main() { let a = [1, 2, 3, 4, 5]; let first = a[0]; // first = 1 let second = a[1]; // second = 2 }
Rust中,访问无效的索引元素会报错,如下:
fn main() { let a = [1, 2, 3, 4, 5]; let b = a[5]; // 错误,只能放为0-4,所以这个代码将无法编译 }
3.2.3 类型转换 (少一个From, Into, TryFrom, TryInto)
Rust中可以使用as进行类型转换。
- 数值类型之间默认不会隐式转换,如果要转换,则需手动使用
as进行转换。 - bool类型可以转换为各种数值类型,
false对应0,true对应1。 - 可以使用
as将char类型转换为各种整型,目标类型小于4字节时,会从高位截断。 - 可以使用
as将u8转换为char类型。 - 可以使用
std::char::from_u32将u32转换为char类型。 - 可以使用
std::char::from_digit将十进制整型转换为char类型。
fn main() { // 数值类型的转换 assert_eq!(10i8 as u16, 10u16); assert_eq!(123u16 as i16, 123i16); // bool类型转换 assert_eq!(false as u32, 0u32); assert_eq!(true as i8, 1i8); // char类型相关转换 assert_eq!('我' as i32, 25105i32); // char转换到i32 assert_eq!('是' as u8, 47u8); // char转换到u8,会被截断 assert_eq!(97u8 as char, 'a'); // u8转换到char assert_eq!(std::char::from_u32(0x2764).unwrap(), '❤'); assert_eq!(std::char::from_digit(4, 10).unwrap(), '4'); }
3.3 函数
3.3.1 函数定义
fn关键字、函数名、函数参数名及其类型(如果有的话)、返回值类型(如果有的话)组成函数签名,加上由一对花括号({})包裹的函数体组成函数。例子如下:
// 一个没有参数,也没有返回值的函数 fn print_line() { println!("++++++++++++++++"); } // 一个有参数,没有返回值的函数 fn print(x: u32) { println!("result is {:?}", x); } // 一个有参数,也有返回值的函数 fn sum(a: u32, b: u32) -> u32 { a + b } // main函数是rust程序的入口函数 fn main() { print_line(); let a = 1u32; let b = 2u32; let r = sum(a, b); print(r); }
Rust中,函数也可以定义在函数内部,如下:
fn calculate(a: u32, b: u32) { println!("a is {:?}", a); println!("b is {:?}", b); // 在函数内部定义函数 fn sum(a: u32, b: u32) -> u32 { a + b } let r = sum(a, b); println!("a + b is {:?}", r); } fn main() { let a = 1u32; let b = 2u32; calculate(a, b); }
3.3.2 语句和表达式
Rust中,语句是执行一个操作但不返回值的指令,表达式则计算并产生一个值。
fn main() { let a = 1u32; // "1u32"就是一个表达式,而“let a = 1u32;”则是一个语句 let b = a + 1; // “a + 1”就是一个表达式,而“let b = a + 1;”则是一个语句 // 下面的代码中, // “b + d”是一个表达式 let c = { let d = 2u32; b + d // 注意:这里是没有分号的 }; // c = 4 }
3.3.3 函数返回值
-
使用
return指定返回值,如下:fn sum(a: u32, b: u32) -> u32 { let r = a + b; return r //可以加分号,也可以不加分号, 所以这行等价于“return r;” } fn main() { let a = 1u32; let b = 2u32; let c = sum(a, b); println!("c = {:?}", c); }特别地,
return关键字不指定值时,表示返回的是(),如下:#![allow(unused)] fn main() { fn my_function() -> () { println!("some thing"); return; // 等价于“return ()” } } -
不使用
return关键字,将返回最后一条执行的表达式的计算结果,如下:fn sum(a: u32, b: u32) -> u32 { println!("a is {:?}", a); println!("b is {:?}", b); a + b // 注意,是没有加分号的 } fn main() { let a = 1u32; let b = 2u32; let c = sum(a, b); println!("c = {:?}", c); }
3.4 注释
在Rust中,注释分为三类:
- 代码注释,用于说明某一块代码功能,读者往往是同一项目的协作者;
- 文档注释,支持markdown,对项目、公共API等进行描述,同时还能提供示例代码,读者是想要了解你项目的人;
- 包和模块注释,文档注释的一种,用于说明当前包和模块的功能,方便用户迅速了解项目。
本节主要简单介绍代码注释和文档注释,对于注释的其它功能,我们后面再深入。
3.4.1 代码注释
代码注释有两种:
(1)行注释,使用//;
(2)块注释,使用/* ... */。
示例如下:
/* * 块注释: * 函数名:sum * 参数:a,b * 返回值类型:u32 */ fn sum(a: u32, b: u32) -> u32 { a + b } fn main() { let a: u32 = 1; let b: u32 = 1; // 行注释:调用sum函数计算a+b的和 let c = sum(a, b); println!("a + b is {:?}", c); }
3.4.2 文档注释
Rust提供了cargo doc命令可以把文档注释转换成html网页,最终展示给用户。文档注释也有文档行注释和文档块注释:
(1)文档行注释,使用///;
(2)文档块注释,使用/** ... */。
示例如下:
// 下面是文档行注释 /// `add_one` 将指定值加1 /// /// # Examples /// /// ``` /// let arg = 5; /// let answer = my_crate::add_one(arg); /// /// assert_eq!(6, answer); /// ``` pub fn add_one(x: i32) -> i32 { x + 1 } // 下面是文档块注释 /** `add_two` 将指定值加2 \``` let arg = 5; let answer = my_crate::add_two(arg); assert_eq!(7, answer); \``` */ pub fn add_two(x: i32) -> i32 { x + 2 } fn main() { let a: i32 = 1; let c = add_one(a); println!("a + 1 is {:?}", c); let d = add_two(a); println!("a + 2 is {:?}", d); }
运行如下命令:
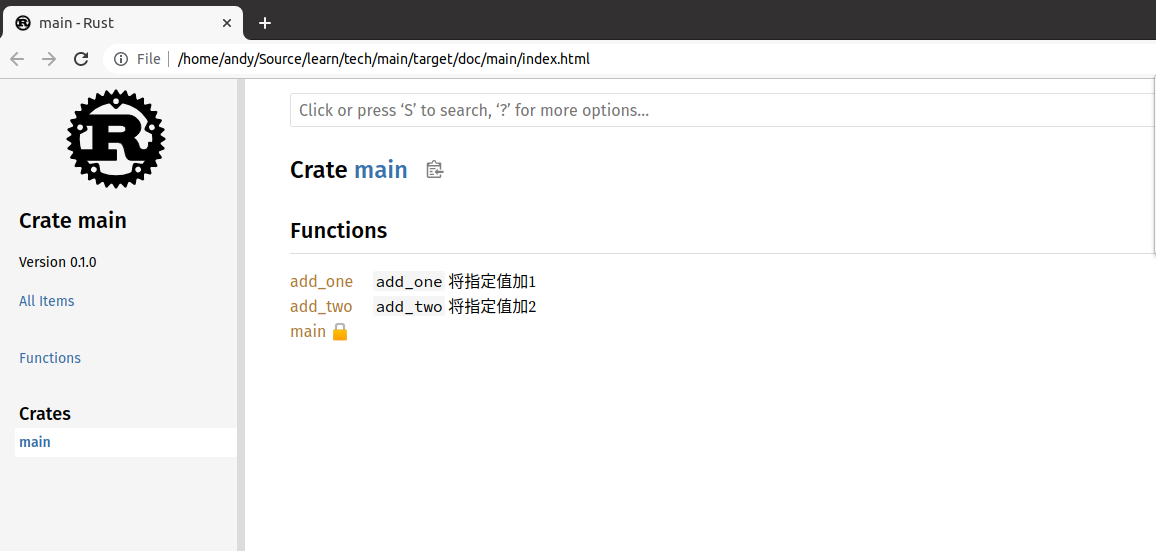
cargo doc --open
将打开上面代码里面文档注释生成的文档,如下图:
3.5 控制流
Rust中的控制流结构主要包括:
if条件判断;loop循环;while循环;for .. in循环。
3.5.1 if条件判断
-
if执行条件判断,示例如下:fn main() { let a = 2u32; if a > 5u32 { println!("a > 5"); } else { println!("a <= 5"); } } -
if - else if处理多重条件,示例如下:fn main() { let a = 3u32; if a > 5u32 { println!("a > 5"); } else if a > 4u32 { println!("a > 4"); } else if a > 3u32 { println!("a > 3"); } else if a > 2u32 { println!("a > 2"); } else if a > 1u32 { println!("a > 1"); } else { println!("a = 1"); } } -
在
let语句中使用ifif是一个表达式,所以可以在let右侧使用,如下:fn main() { let a = 3u32; let a_bigger_than_two: bool = if a > 2u32 { true } else { false }; if a_bigger_than_two { println!("a > 2"); } else { println!("a <= 2"); } }
3.5.2 loop循环
-
loop重复执行代码
fn main() { // 一直循环打印 again! loop { println!("again!"); } } -
使用
break终止循环fn main() { let mut counter = 0; loop { println!("counter = {:?}", counter); counter += 1; if counter == 10 { break; // 将终止循环 } } }上面的代码将打印10次,遇到
break后终止循环。另外,break也可以返回值,如下:fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {result}"); } -
使用
continue可以直接跳到下一轮循环fn main() { let mut x = 0; // 此循环将只打印10以内的奇数 loop { x += 1; if x == 10 { break; } if x % 2 == 0 { continue; // 将直接跳到下一轮循环 } println!("{}", x); } }
3.5.3 while条件循环
-
while条件循环执行代码,当条件不满足时结束循环,如下:fn main() { let mut cnt = 0u32; while cnt < 10 { println!("cnt = {:?}", cnt); cnt += 1; } } -
在
while循环中也可以使用break和continue,如下:fn main() { let mut x = 0; while x < 10 { x += 1; println!("{}", x); if x % 2 == 0 { continue; // 跳到下一轮循环 } if x > 8 { break; // 提前结束 } } }
3.5.4 for .. in 循环
for循环用来对一个集合的每个元素执行一些代码,使用方式如下:
fn main() { let a = [10, 20, 30, 40, 50]; for item in a { println!("the value is: {:?}", item); } }
3.6 Rust内存模型
3.6.1 Rust程序内存布局
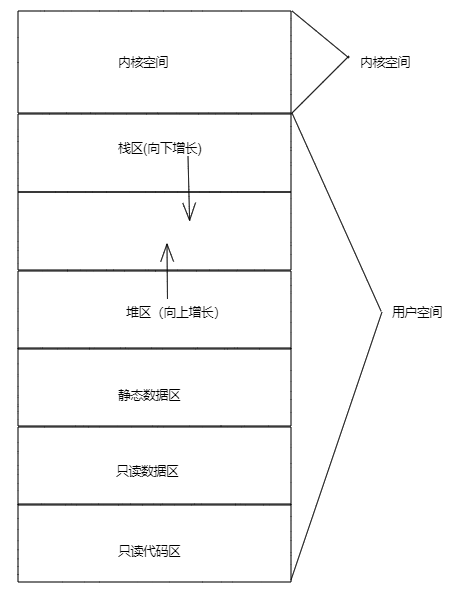
上图是一张Linux系统上Rust程序的内存布局图。在Linux操作系统中,会划分固定的区域给内核使用,即上图中的内核空间;应用程序使用的是用户空间。
Rust程序使用的内存空间分为如下:
- 只读代码区(Instructions):存放可执行代码的区域。
- 只读数据区(Literals):存放代码的文字常量的区域。
- 静态数据区(Static Data):一般的静态函数、静态局部变量、静态全局变量的存放区域,在程序启动的时候初始化。
- 堆区(Heap):程序代码中动态分配的内存,在程序运行时申请,该区域向上增长。
- 栈区(Stack):该区域存放函数调用的参数、局部变量和返回地址等信息,在编译阶段分配,向下增长。
3.6.2 栈和堆
1. 栈和栈帧
“栈和栈帧属于操作系统的概念,由操作系统进行管理,栈空间以后进先出的顺序存储数据。将数据放到栈上就做入栈,将数据移出栈就做出栈。每次调用函数时,操作系统会在栈顶创建一个栈帧来保存函数的上下文数据(主要是函数内部声明的局部变量),函数返回时返回值也会存储在该栈帧中。当函数调用者取得该函数返回值后,栈帧会被释放。”引用自《Rust入门秘籍》。
fn f1(a: i32, b: i32) -> i32 { let c: i32 = 1; let r = a + b + c; r } fn f2(a: i32, b: i32) -> i32 { let c = a - b; let r = c % 2; r } fn main() { let a = 5i32; let b = 1i32; let _r = f1(a, b); let _r = f2(a, b); }
对于上面的代码,在执行let _r = f1(a, b);和let _r = f2(a, b);这两行代码时的栈帧示意图如下:
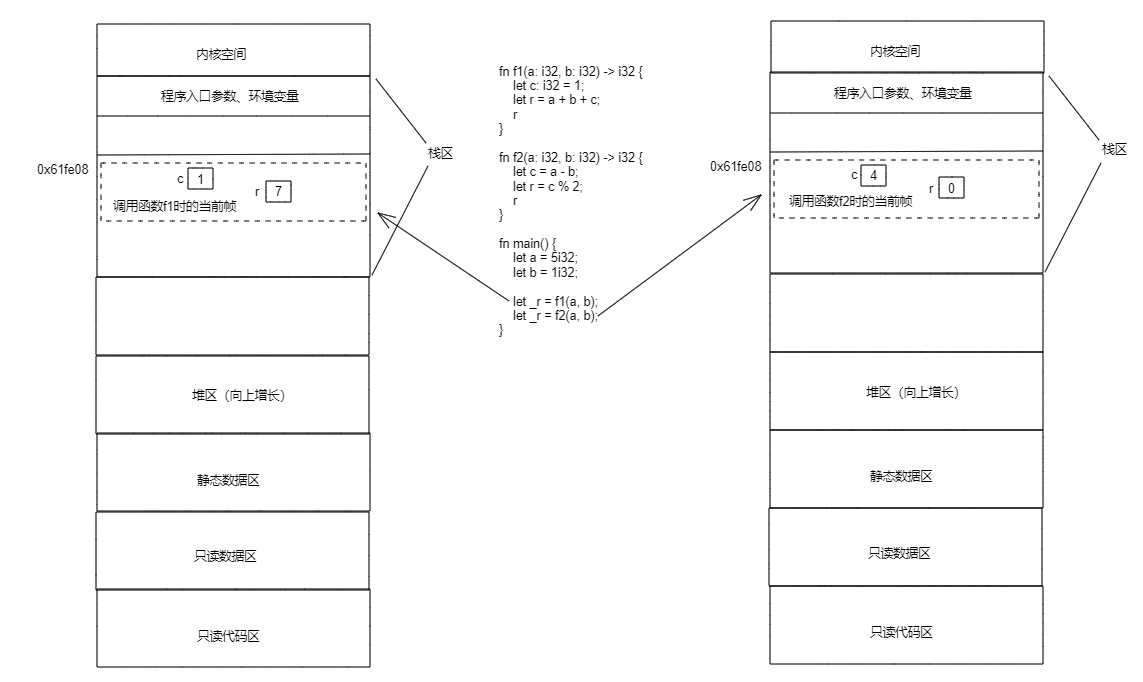
这里需要注意的是两个帧对应同样的内存地址,这是因为在调用完f1函数后,其对应的栈帧释放(释放的实际意义就是这段内存可以被重新分配了),然后调用f2函数为其分配栈帧时从同样的地址进行分配。
2. 堆
堆空间和栈空间不同,不由操作系统管理,在需要时申请,不需要时释放。申请和释放堆内存是一件困难的事情,尤其当程序代码较多时。只申请堆内存而不释放会造成内存泄露,内存泄露过多会造成内存耗尽而崩溃。错误地释放在使用的内存也会造成程序运行错误(或直接无法运行)。
有些编程语言提供垃圾管理回收器(GC)来自动回收不再使用的堆内存,有些语言必须完全由程序员在代码中手动申请和释放内存。
Rust没有GC,但通过其独特的机制管理内存,程序员不用手动申请和释放堆内存。
3. Rust如何使用堆和栈
栈中存储的所有数据都必须占用(在编译时就)已知且固定的大小。编译时大小未知或可能变化的数据,存储在堆上。
数据存放到栈上时,是直接将数据放到栈内存的。
当数据需要存放到堆上时,内存分配器则是根据数据的大小,在堆内存找到合适大小的空区域存放,把它标记为已使用,并返回一个表示该位置地址的指针。该指针存储在栈上,当需要访问具体的数据时,必须先访问指针,然后通过指针找到堆上的位置,从而访问数据。这个过程可以用下图表示:
3.7 所有权
3.7.1 所有权介绍
所有权是Rust最为与众不同的特性,它让Rust无需垃圾回收即可保证内存安全。
1. 所有权规则
Rust所有权的规则如下:
- Rust中的每个值都有一个被称为其所有者的变量,即值的所有者是某个变量;
- 值在任何时刻有且仅有一个所有者;
- 当所有者离开作用域后,这个值将被丢弃。
fn main() { let a: u32 = 8; let b: String = String::from("hello"); let c: Vec<u8> = vec![1, 2, 3]; }
上面的代码中,a就是8的所有者,b是String::from("hello")的所有者,c则是vec![1, 2, 3]的所有者。
注意:b是String::from("hello")的所有者,但是b不是字符串"hello"的所有者。同理,c是vec![1, 2, 3]的所有者,但不是[1, 2, 3]的所有者。至于为什么,后续内容(String类型部分)会进行讲解。
2. 变量的作用域
变量作用域是变量在程序中有效的范围。一对花括号表示的范围就是作用域,变量有效的范围就是从创建开始,到离开作用域结束。
示例1:
fn f() { let b = 1u32; // ---------------------------------| let c = 2u32; // -----------| | // | | // | |--- b的作用域范围 println!("b = {:?}", b); // |-- c的作用域范围 | println!("c = {:?}", c); // | | // -----------|---------------------| } fn main() { let a: u32 = 8; // ------------------------------| println!("a = {:?}", a); // | // |---- a的作用域范围 f(); // | // --------------------------------------------------| }
示例2:
fn main() { let a = 8u32; // --------------------------| { // | let b = 5u32; // -------| | println!("a = {:?}", a); // |-- b的作用域范围 | println!("b = {:?}", b); // | |---- a的作用域范围 // -------| | } // | println!("a = {:?}", a); // | // --------------------------| }
3. String类型
1)String类型的创建有下面三种方式:
String::fromto_stringString::new
fn main() { let s1 = String::from("Hello"); // 方法一 let s2 = "Hello".to_string(); // 方法二 let mut s3 = String::new(); // 方法三 s3.push('H'); s3.push('e'); s3.push('l'); s3.push('l'); s3.push('o'); s3.push('!'); println!("s1: {:?}", s1); println!("s2: {:?}", s2); println!("s3: {:?}", s3); }
2)String类型的本质
Rust标准库中,String类型的定义如下:
#![allow(unused)] fn main() { pub struct String { vec: Vec<u8>, } }
Vec类型的定义如下:
#![allow(unused)] fn main() { pub struct Vec<T> { buf: RawVec<T>, len: usize, // 长度 } }
RawVec定义则类似于如下(为了更好地说明String类型,下面的定义用简化的代码):
#![allow(unused)] fn main() { struct RawVec<T> { ptr: NonNull<T>, // 指针 cap: usize, // 容量 } }
那对于整个String类型,可以用伪代码表示如下:
#![allow(unused)] fn main() { struct String { v: struct Vec<u8> { raw_vec: RawVec{ptr: NonNull<u8>, cap: usize}, len: usize, } } }
更进一步地简化,可以得到String类型本质如下:
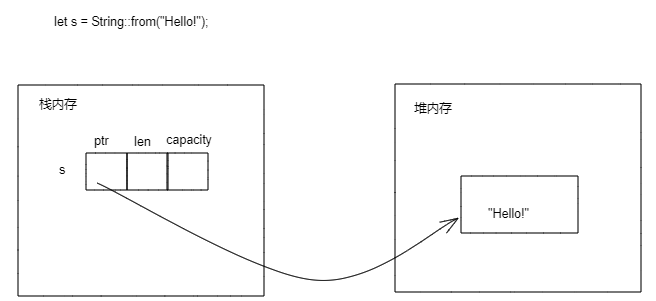
#![allow(unused)] fn main() { struct String { ptr:NonNull<u8>, cap: usize, len: usize, } }
所以String类型本质是三个字段:一个指针,一个容量大小,一个长度大小。
3)内存分配
在Rust中,编译时大小确定的数据放在栈上,编译时大小不能确定的数据放在堆上。考虑如下代码:
fn main() { let mut s = String::new(); s.push('A'); s.push('B'); println!("{s}"); // 打印AB }
在第2行定义String类型时,并不能确定最终字符串的大小,所以字符串内容本身应该存储在堆上。结合String类型的本质的内容,可以得到String类型的存储如下:
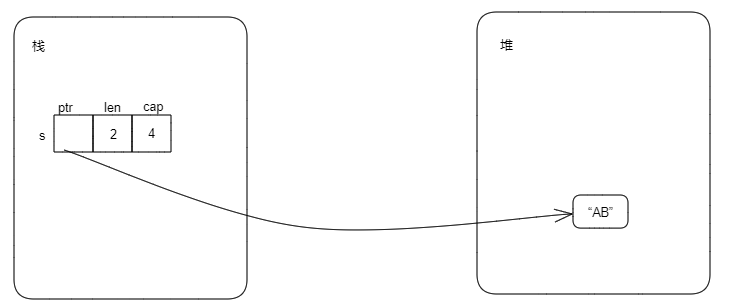
String类型本身是三个字段(指针、长度、容量),在编译时是已知的大小,存储在栈上;String类型绑定的字符串(在上面代码中是“AB”)在编译时大小未知,是运行时在堆上分配内存,分配后的内存地址保存在String类型的指针字段中,内存大小保存在cap字段中,内存上存储的字符串长度保存在len字段中。
4. move语义
Rust所有权规则第二条,在任意时刻,值有且仅有一个所有者。那么当一个变量赋给另外一个变量时发生了什么?
1)完全存储在栈上的类型
考虑如下代码:
fn main() { let x = 5u32; let y = x; println!("x: {:?}, y: {:?}", x, y); }
x和y都是u32类型,在编译时知道大小,都存储在栈上。代码第2行是将5绑定到变量x上,第3行则是通过自动拷贝的方式将5绑定到y上(先拷贝x的值5,然后将拷贝后得到的5绑定到y上)。所以,当let y = x发生后,这段代码里面最后有两个值5,分别绑定到了x和y上。
2)涉及到堆存储的类型
再考虑如下代码:
fn main() { let s = "Hello world!".to_string(); let s1 = s; // println!("s: {:?}", s); // 此行打开编译将报错 println!("s1: {:?}", s1); }
s是String类型,字符串"Hello world"是存储在堆内存上的,其内存布局如下:
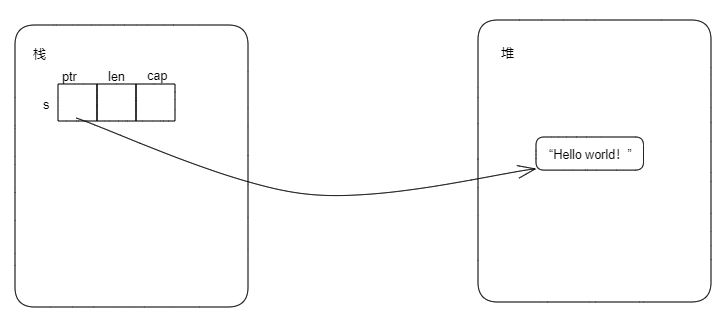
当执行let s1 = s后,内存布局如下:
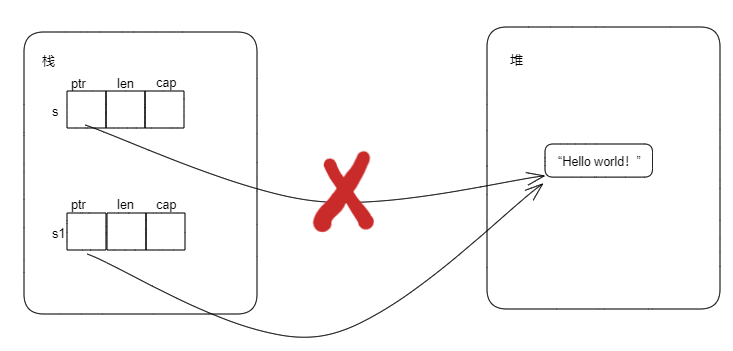
当let s1 = s执行后,就发生了所有权的转移,String类型值的所有权从s转移到了s1。此时Rust认为原来的s不再有效。因此,上面代码第4行打开编译将会出错。
5. 浅拷贝与深拷贝
1)浅拷贝
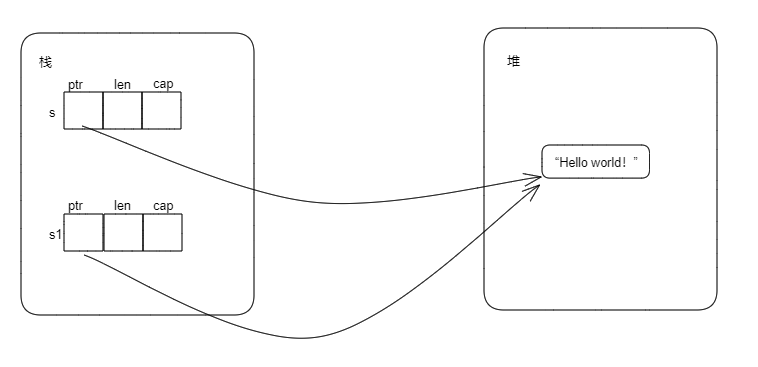
只拷贝栈上的内容,就叫做浅拷贝。
对于上面的String类型,执行let s1 = s后,只把s的ptr、len、cap中的值拷贝给s1的ptr、len、cap的值,这种就叫做浅拷贝。浅拷贝发生后,s的ptr和s1的ptr都指向同样的堆内存。内存布局如下:
2)深拷贝
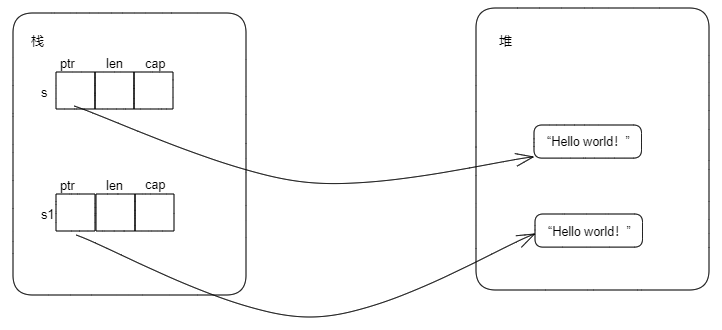
除了拷贝栈上的内容外,还拷贝堆内存中的内容,就叫做深拷贝。
对于上面的String类型,执行let s1 = s后,除了把s的len、cap中的值拷贝给s1的len、cap外,还在堆上重新分配一块内存,将s的ptr指向的堆内存的内容拷贝到这块内存,然后s1的ptr指向这块内存,这种拷贝就叫做深拷贝。深拷贝发生后,s的ptr和s1的ptr指向不同的堆内存,但是堆内存中存储的内容一样。深拷贝发生后的内存布局如下:
显然,Rust中变量赋值(Rust中叫所有权转移)使用的是浅拷贝。
6. Clone
当需要拷贝堆上的数据时,可以使用clone方法,完成深拷贝的操作,如下:
fn main() { let s = "Hello world!".to_string(); let s1 = s.clone(); // 这将发生深拷贝 println!("s: {:?}", s); println!("s1: {:?}", s1); }
不过不是所有的类型都能使用clone方法进行深拷贝,只有实现了Clone trait的类型才能调用该方法。
7. Copy
按照Rust所有权规则第二条,在任意时刻,值有且仅有一个所有者。所以当let b = a发生时,就将变量a拥有的值移到了b上,此时a应该回到未初始状态,但实际情况并不一定。不一定的原因是,部分类型实现了Copy trait,在值移动时会对值进行自动拷贝,能让变量a仍拥有原来的值。
Rust中,默认实现了Copy trait的类型有:
- 所有整数类型,比如
u32; - 所有浮点数类型,比如
f64; - 布尔类型,
bool,它的值是true和false; - 字符类型,
char; - 元组,当且仅当其包含的类型也都是
Copy的时候。比如(i32, i32)是Copy的,但(i32, String)不是; - 数组,当且仅当其包含的类型也都是
Copy的时候。比如[i32; 5]是Copy的,但[String; 5]不是; - 共享指针类型或共享引用类型。
8. 所有权和函数
1)将值传给函数
在将值传递给函数时,和变量赋值一样会发生值的移动(或复制),如下:
fn main() { let s = String::from("hello"); takes_ownership(s); // println!("s: {:?}", s); // 打开编译会报错,因为s的所有权在上一行已经转移到take_ownership函数中了 let x = 5; makes_copy(x); println!("x: {:?}", x); // 不会报错,因为上一行将x传到makes_copy函数时会自动拷贝x的值到函数中 } fn takes_ownership(some_string: String) { println!("{}", some_string); } fn makes_copy(some_integer: i32) { println!("{}", some_integer); }
2)返回值和作用域
函数的返回值也可以转移所有权,如下:
fn main() { let s1 = gives_ownership(); // gives_ownership 将返回值转移给 s1 let s2 = String::from("hello"); // s2 进入作用域 let s3 = takes_and_gives_back(s2); // s2 被移动到 takes_and_gives_back 中, // 它也将返回值移给 s3 } // 这里,s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走,所以什么也不会发生。s1 离开作用域并被丢弃 fn gives_ownership() -> String { // gives_ownership 会将返回值移动给调用它的函数 let some_string = String::from("yours"); // some_string 进入作用域。 some_string // 返回 some_string 并移出给调用的函数 } // takes_and_gives_back 将传入字符串并返回该值 fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域 a_string // 返回 a_string 并移出给调用的函数 }
关于所有权的总结:将值赋给另一个变量时移动它。当持有堆中数据值的变量离开作用域时,其值将被drop函数(后续讲解)清理掉,除非数据被移动为另一个变量所有。
3.7.2 引用与借用
考虑如下代码:
fn main() { let s2 = String::from("hello"); print(s2); // println!("s2 is {:?}", s2); //打开报错,s2的所有权在上一行已经移动到print函数, //此处无法再使用 } fn print(s: String) { println!("s is: {:?}", s); }
第4行打开注释编译将发送错误,因为s2的所有权在第3行已经转移到print函数中了,s2将不再有效,因此第4行不能再使用。
如果要在调用print函数后仍然能使用s2,根据本书目前学过的Rust知识,则需要将所有权再从函数转移到变量,然后使用,代码如下:
fn main() { let s2 = String::from("hello"); let s3 = print(s2); println!("s3 is {:?}", s3); } fn print(s: String) -> String { println!("s is: {:?}", s); s //将s的所有权返回 }
除了这种转移所有权的方式外,Rust还提供了引用的方式可以借用数据的所有权。
1. 引用与借用
引用本质上是一个指针,它存储一个地址,通过它可以访问存储在该地址上属于其它变量的数据。与指针不同的是,引用确保指向某个特性类型的有效值。对于一个变量的引用就是在此变量前面加上&符合。
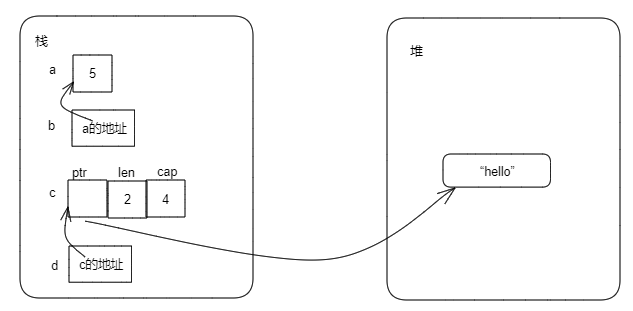
#![allow(unused)] fn main() { let a = 5u32; let b = &a; // b是对a的引用 let c = String::from("hello"); let d = &c; // d 是对c的引用 }
上面代码中,变量a、b、c、d的内存布局如下:
获取变量的引用,称之为借用 。通过借用,允许使用被引用变量绑定的值,同时又没有移动该变量的所有权。前面的示例代码可以变成如下:
fn main() { let s2 = String::from("hello"); let s3 = &s2; //s3是对s2的借用,s3并不拥有String::from("hello")的所有权,s2的所有权没有改变 print(s3); //在函数中使用s3 println!("s2 is {:?}", s2); //仍然可以使用s2 } fn print(s: &String) { println!("s is: {:?}", s); }
在一个范围对变量进行多个引用是可以的,如下:
fn main() { let s2 = String::from("hello"); let s3 = &s2; //s3是对s2的借用,s3并不拥有String::from("hello")的所有权,s2的所有权没有改变 let s4 = &s2; //s4也是对s2的借用 let s5 = &s2; //s5也是对s2的借用 print(s3); //在函数中使用s3 println!("s2 is {:?}", s2); //仍然可以使用s2 println!("s4 is {:?}", s4); println!("s5 is {:?}", s5); } fn print(s: &String) { println!("s is: {:?}", s); }
引用只能使用变量,并不允许改变变量的值,如果需要改变变量,需要使用可变引用(下节内容),下面的代码会报错:
fn main() { let s = String::from("hello"); change(&s); } fn change(some_string: &String) { some_string.push_str(", world"); //借用不允许改变变量的值,此行报错 }
与引用相对的是解引用,符号为*,本书后续讲解。
2. 可变引用
2.1 使用可变引用
可以通过可变引用改变变量的值,对一个变量加上&mut就是对其的可变引用,示例如下:
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); // 可变引用,可以对变量进行修改 }
2.2 引用的作用域
前文讲过变量的作用域是从定义开始到花括号结束的位置,如:
{
...
let a = 1u32; // a的作用域开始位置
...
} // 花括号之前为a的作用域结束位置
引用的作用域和变量的作用域有些区别,在老版本编译器(Rust 1.31 之前)中,引用的作用域和变量的作用域一样,也是从定义的位置开始到花括号之前结束,如下:
{
...
let s = "Hello".to_string();
let r = &s; // r的作用域开始位置
....
}// 花括号之前为r的作用域结束位置
在新版本编译器中,引用作用域的结束位置从花括号变成最后一次使用的位置,如下:
{
...
let s = "Hello".to_string();
let r = &s; // r的作用域开始位置
println!("r = {:?}", r); // r的作用域结束位置
... //后面不再使用 r
}
2.3 使用可变引用的限制
(1)限制一:同一作用域,特定数据只能有一个可变引用。如下代码会报错:
fn main() { let mut s1 = String::from("hello"); let r1 = &mut s1; // 可变引用 let r2 = &mut s1; // 错误,同一作用域变量只允许被进行一次可变借用 println!("{}, {}", r1, r2); }
但是下面的代码可以的(新老编译器都可以):
fn main() { let mut s = String::from("hello"); { let r1 = &mut s; r1.push('!'); println!("r1: {:?}", r1); } // r1 在这里离开了作用域,所以我们完全可以创建一个新的引用 let r2 = &mut s; r2.push('!'); println!("r2: {:?}", r2); }
下面的代码在新编译器中也是可以的:
fn main() { let mut s = String::from("hello"); let r1 = &mut s; r1.push('!'); println!("r1: {:?}", r1); // 后面的代码不再使用r1, 新编译中r1作用域在此处结束, // 所以完全可以在后面创建一个新的引用 let r2 = &mut s; r2.push('!'); println!("r2: {:?}", r2); //老编译器中,r1的作用域在花括号前结束,所以老编译器中此代码编译不过 }
(2)限制二:同一作用域,可变引用和不可变引用不能同时存在。如下代码编译错误:
fn main() { let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 let r3 = &mut s; // 大问题,同时存在两个s的引用和一个可变引用 println!("{}, {}", r1, r2); println!("{}", r3); }
下面的代码在新编译器中是可以的:
fn main() { let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 println!("{} and {}", r1, r2); // 此位置之后 r1 和 r2 不再使用, 新编译器中: r1和r2离开了其作用域 let r3 = &mut s; // 没问题,因为r1和r2已不存在,没有同时存在对s的引用和可变引用 println!("{}", r3); } // 老编译器中: r1、r2、r3的作用域都是在花括号之前结束
Rust这样设计的原因:
通过此设计,防止同一时间对同一数据存在多个可变引用。 这样Rust 在编译时就避免了数据竞争。数据竞争(data race) 类似于竞态条件,它可由这三个行为造成:
- 两个或更多指针同时访问同一数据。
- 至少有一个指针被用来写入数据。
- 没有同步数据访问的机制。
数据竞争会导致未定义行为,难以在运行时追踪,并且难以诊断和修复;Rust 避免了此情况的发生,因为它甚至不会编译存在数据竞争的代码!
3. 悬垂引用
3.1 什么是悬垂引用(悬垂指针)?
在具有指针的语言中(如C/C++),很容易通过释放内存但是保留指向它的指针而错误的生成一个悬垂指针。例如有如下C代码:
#include <stdio.h>
#include<stdlib.h>
int main()
{
char *ptr=(char *)malloc(10*sizeof(char));
ptr[0]='h';
ptr[1]='e';
ptr[2]='l';
ptr[3]='l';
ptr[4]='o';
ptr[5]='\0';
printf ("string is: %s\n",ptr);
free(ptr); //释放了ptr所指向的内存
printf ("string is: %s\n",ptr); // 危险的行为: 使用已经释放的内存
return 0;
}
在执行第14行前,其内存布局为:

当执行第14行后,变成如下:
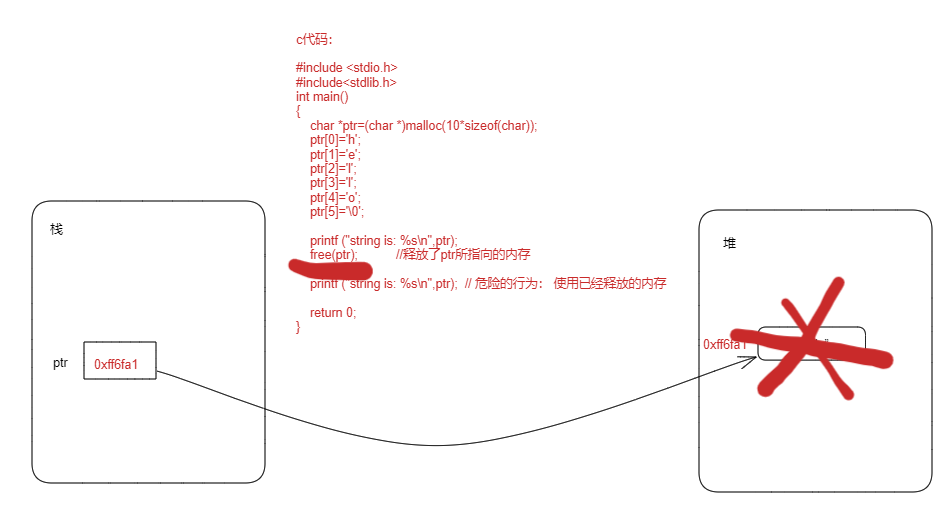
第14行执行后,ptr就变成了一个悬垂指针(或者叫悬垂引用),然后在第16行继续使用ptr,则会发生错误。
3.2 在 Rust 中,编译器确保引用永远不会变成悬垂状态。
如下代码因为会产生悬垂引用,编译将不会通过:
fn main() { let reference_to_nothing = dangle(); } fn dangle() -> &String { let s = String::from("hello"); &s // s在花括号前离开作用域,将会变得无效,返回的指向s的引用将是一个悬垂引用 }
思考:为什么下面的代码是正确的 ?
fn main() { let s = no_dangle(); println!("s = {:?}", s); } fn no_dangle() -> String { let s = String::from("hello"); s } // 此处s虽然离开了函数这个作用域范围,但是它的所有权是被转移出去了,值并没有释放
4. 引用的规则总结
引用的规则可以总结如下:
- 在任意给定时间,要么 只能有一个可变引用,要么 只能有多个不可变引用。
- 引用必须总是有效的(不能是悬垂引用)。
3.7.3 Slice类型
Slice(切片)类型,表示引用集合中一段连续的元素序列。Slice是一类引用,没有所有权。Rust常见类型中,有三种支持Slice的操作,分别是String、数组、Vec类型。
1. Slice类型
假定s是可被切片的数据,则对应的操作有:
s[n1..n2]:获取s中index=n1到index=n2(不包括n2)之间的所有元素;s[n1..]:获取s中index=n1到最后一个元素之间的所有元素;s[..n2]:获取s中第一个元素到index=n2(不包括n2)之间的所有元素;s[..]:获取s中所有元素;- 其他表示包含范围的方式,如
s[n1..=n2]表示取index=n1到index=n2(包括n2)之间的所有元素。
Rust中几乎总是使用切片数据的引用。切片数据的引用对应的数据类型描述为&[T]或&mut [T],前者不可通过Slice引用来修改源数据,后者可修改源数据。示例如下:
fn main(){ let mut arr = [11,22,33,44]; let arr_slice1 = &arr[..=1]; println!("{:?}", arr_slice1); // [11,22]; let arr_slice2 = &mut arr[..=1]; arr_slice2[0] = 1111; println!("{:?}", arr_slice2);// [1111,22]; println!("{:?}", arr);// [1111,22,33,44]; }
Slice类型是一个胖指针,包含两个字段:
- 第一个字段是指向源数据中切片起点元素的指针;
- 第二个字段是切片数据中包含的元素数量,即切片的长度。
2. String的切片类型
String的切片类型为&str而不是&String,其使用方式如下:
fn main() { let s = String::from("hello world!"); let s1 = &s[6..]; // 切片类型&str let s2 = &s; // 引用类型&String println!("{:?}", s1); println!("{:?}", s2); }
&str和&String的内存布局如下:
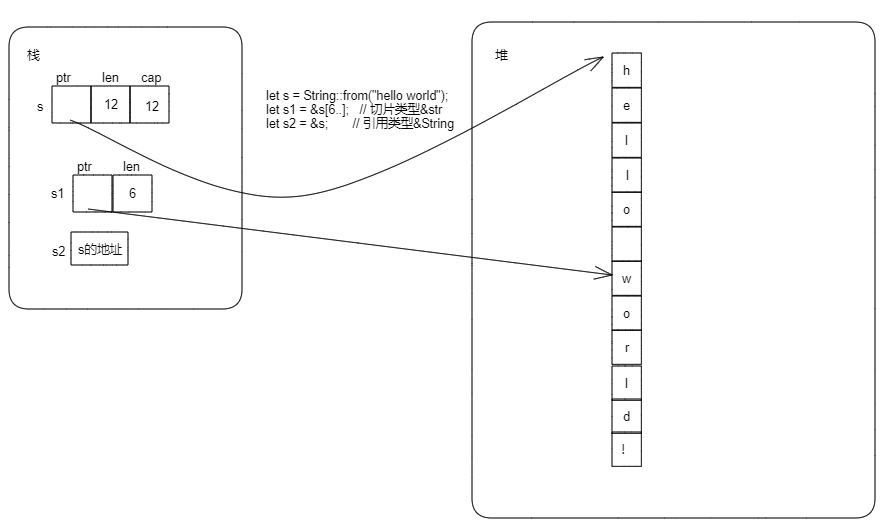
3. 其它Slice
数组的Slice,如下:
fn main() { let a: [u32; 5] = [1, 2, 3, 4, 5]; let b = &a[1..3]; println!("b: {:?}", b); }
Vec的Slice,如下:
fn main() { let v: Vec<u32> = vec![1, 2, 3, 4, 5]; let b = &v[1..3]; println!("b: {:?}", b); }
3.8 复合数据类型
Rust中可以通过结构体或者枚举来构造复杂的数据类型,结构体使用struct 关键字,枚举使用enum关键字。通过结构体或者枚举将多个值组合在一起。
3.8.1 结构体
结构体(structure,缩写成 struct)有 3 种类型,使用 struct 关键字来创建:
- 元组结构体(tuple struct),事实上就是具名元组而已。
- 经典的 C 语言风格结构体(C struct)。
- 单元结构体(unit struct),不带字段,在泛型中很有用。
1. 定义和实例化
1.1 元组结构体的定义和实例化
下面是定义一个元组结构体,用来表示颜色。
#![allow(unused)] fn main() { struct Color(i32, i32, i32); // 实例化元组结构体 let color = Color(1, 1, 1); }
使用元组结构体的特点是,给定元组具体的名字,可以和同类元组内的类型的元组做区分。
#![allow(unused)] fn main() { struct Color(i32, i32, i32); struct Point(i32, i32, i32); // 实例化元组结构体 let color = Color(1, 1, 1); let point = Point(1, 1, 1); }
可以看到Color 和Point虽然元组内的元素都是i32,但是给定了(i32, i32,i32)这个元组两个不同的结构体名称,所以Color和Point不是同一种类型。
#[derive(Debug, Eq, PartialEq)] pub struct Color(i32, i32, i32); #[derive(Debug, Eq, PartialEq)] pub struct Point(i32, i32, i32); fn main() { assert_eq!(Color(1, 1, 1), Point(1, 1, 1)); // error, 判断两个元组结构体是不是相等,rust将不同类型名称的结构体看作是不一样的结构体,虽然,结构内的元素都是一样的。 }
1.2 经典的C结构体的定义和初始化
结构体内的每个字段都是命名字段,使得访问和修改更直观。
#![allow(unused)] fn main() { // 定义结构体 struct Person { name: String, age: u32, height: f32, } // 结构体实例化 let alice = Person { name: String::from("Alice"), age: 30, height: 1.65, }; }
思考:结构体内的数据可以用不同的类型,使用C结构和元组结构体的区别在于,要给结构内的每个字段给予名字来表明其意义。
1.3 单元结构体的定义和初始化
这种结构体没有任何字段。它们通常用于实现特定的行为,而不是表示数据。
#![allow(unused)] fn main() { // 定义结构体 struct Dummy; // 结构体实例化 let dummy = Dummy; }
2. 方法
这三类结构体的方法的定义和使用方式相同,示例如下:
2.1 元组结构体的方法
#![allow(unused)] fn main() { struct Color(u8, u8, u8); impl Color { fn print(&self) { println!("Color: ({}, {}, {})", self.0, self.1, self.2); } } let red = Color(255, 0, 0); red.print(); // 输出:Color: (255, 0, 0) }
2.2 类C结构体的方法
#![allow(unused)] fn main() { struct Person { name: String, age: u32, } impl Person { fn greet(&self) { println!("Hello, my name is {} and I'm {} years old.", self.name, self.age); } } let alice = Person { name: String::from("Alice"), age: 30, }; alice.greet(); // 输出:Hello, my name is Alice and I'm 30 years old. }
2.3 单元结构体的方法
#![allow(unused)] fn main() { struct Dummy; impl Dummy { fn do_something(&self) { println!("Doing something..."); } } let dummy_instance = Dummy; dummy_instance.do_something(); // 输出:Doing something... }
3.7.2 枚举类型
1. 定义和实例化
1.1 枚举的定义
枚举允许在一个数据类型中定义多个变量。这在表示多种可能情况时非常有用。每个枚举成员可以具有关联的数据。
#![allow(unused)] fn main() { enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(u8, u8, u8), } }
1.2 枚举的实例化
要创建枚举的实例,需要指定要使用的成员以及其关联的数据(如果有)。
#![allow(unused)] fn main() { let msg = Message::Write(String::from("Hello, Rust!")); }
2. 方法
与结构体类似,也可以为枚举定义方法。
#![allow(unused)] fn main() { impl Message { fn process(&self) { match self { Message::Quit => println!("Quit"), Message::Move { x, y } => println!("Move to ({}, {})", x, y), Message::Write(text) => println!("Write: {}", text), Message::ChangeColor(r, g, b) => println!("Change color to ({}, {}, {})", r, g, b), } } } // 调用方法 msg.process(); // 输出:Write: Hello, Rust! }
3. 控制流
3.1 Match
Rust 中有一个特殊的控制流结构,叫做 match。它用于匹配枚举成员并针对每个成员执行相应的代码。
#![allow(unused)] fn main() { match msg { Message::Quit => println!("Quit"), Message::Move { x, y } => println!("Move to ({}, {})", x, y), Message::Write(text) => println!("Write: {}", text), Message::ChangeColor(r, g, b) => println!("Change color to ({}, {}, {})", r, g, b), } }
match 表达式需要穷举所有可能的枚举成员,这有助于确保代码的完整性和安全性。在某些情况下,如果不需要处理所有枚举成员,可以使用 _ 通配符来匹配任何未明确指定的成员。
#![allow(unused)] fn main() { match msg { Message::Write(text) => println!("Write: {}", text), _ => println!("Other message"), } }
3.2 if let
除了 match 语句之外,Rust 还提供了 if let 语法,用于简化某些模式匹配的情况。if let 对于只关心单个枚举变体的情况特别有用,这样可以避免编写繁琐的 match 语句。if let 可以将值解构为变量,并在匹配成功时执行代码块。
下面是一个使用 Option 枚举的示例:
fn main() { let some_number = Some(42); // 使用 match 语句 match some_number { Some(x) => println!("The number is {}", x), _ => (), } // 使用 if let 语句 if let Some(x) = some_number { println!("The number is {}", x); } }
在这个示例中,if let 语法让代码更简洁,因为只关心 Some 变体。这里还可以使用 else 子句处理未匹配的情况。
fn main() { let some_number: Option<i32> = None; if let Some(x) = some_number { println!("The number is {}", x); } else { println!("No number found"); } }
在此示例中,由于 some_number 是 None,if let 语句不匹配,因此将执行 else 子句,输出 "No number found"。
if let 可以与 Result 枚举一起使用,以便更简洁地处理错误。当只关心 Ok 或 Err 变体之一时,这特别有用。以下是一个处理 Result 枚举的示例。
定义一个可能返回错误的函数:
#![allow(unused)] fn main() { fn divide(numerator: f64, denominator: f64) -> Result<f64, String> { if denominator == 0.0 { Err(String::from("Cannot divide by zero")) } else { Ok(numerator / denominator) } } }
接下来,我们使用 if let 处理成功的情况:
#![allow(unused)] fn main() { let result = divide(4.0, 2.0); if let Ok(value) = result { println!("The result is {}", value); } }
在这种情况下,由于除法操作成功,if let 语句将匹配 Ok 变体,并输出结果。如果只关心错误情况,可以使用 if let 匹配 Err 变体:
#![allow(unused)] fn main() { let result = divide(4.0, 0.0); if let Err(error) = result { println!("Error: {}", error); } }
在这种情况下,由于除法操作失败,if let 语句将匹配 Err 变体,并输出错误消息。
使用 if let 处理 Result 可以简化错误处理,特别是当只关心 Ok 或 Err 变体之一时。然而,请注意,对于更复杂的错误处理逻辑,match 语句或 ? 运算符可能更适合。
4. 常用的枚举类型
Rust 标准库中有一些常用的枚举类型,例如 Option 和 Result。
4.1 Option:表示一个值可能存在或不存在。其成员为 Some(T)(其中 T 是某种类型)和 None。
#![allow(unused)] fn main() { fn divide(numerator: f64, denominator: f64) -> Option<f64> { if denominator == 0.0f64 { None } else { Some(numerator / denominator) } } let result = divide(4.0, 2.0); match result { Some(value) => println!("The result is {}", value), None => println!("Cannot divide by zero"), } }
4.2 Result:表示一个操作可能成功或失败。其成员为 Ok(T)(其中 T 是某种类型)和 Err(E)(其中 E 是错误类型)。
#![allow(unused)] fn main() { fn divide_result(numerator: f64, denominator: f64) -> Result<f64, String> { if denominator == 0.0f64 { Err(String::from("Cannot divide by zero")) } else { Ok(numerator / denominator) } } let result = divide_result(4.0, 0.0); match result { Ok(value) => println!("The result is {}", value), Err(error) => println!("Error: {}", error), } }
这些枚举类型有助于更安全地处理可能出现的错误情况,避免在代码中使用不安全的值(如空指针)。
3.9 泛型
泛型是具体类型或者其它属性的抽象代替,用于减少代码的重复。在编写Rust代码时,可以用泛型来表示各种各样的数据类型,等到编译阶段,泛型则被替换成它所代表的的具体的数据类型。
3.9.1 函数定义中的泛型
如果没有泛型,当为不同的类型定义逻辑相同的函数时,可能如下:
fn return_i8(v: i8) -> i8 { v } fn return_i16(v: i16) -> i16 { v } fn return_i32(v: i32) -> i32 { v } fn return_i64(v: i64) -> i64 { v } fn return_u8(v: u8) -> u8 { v } fn return_u16(v: u16) -> u16 { v } fn return_u32(v: u32) -> u32 { v } fn return_u64(v: u64) -> u64 { v } fn main() { let _a = return_i8(2i8); let _b = return_i16(2i16); let _c = return_i32(2i32); let _d = return_i64(2i64); let _e = return_u8(2u8); let _f = return_u16(2u16); let _g = return_u32(2u32); let _h = return_u64(2u64); }
使用泛型后,可以在函数定义时使用泛型,在调用函数的地方指定具体的类型,如下:
fn return_value<T>(v: T) -> T{ v } fn main() { let _a = return_value(2i8); let _b = return_value(2i16); let _c = return_value(2i32); let _d = return_value(2i64); let _e = return_value(2u8); let _f = return_value(2u16); let _g = return_value(2u32); let _h = return_value(2u64); }
3.9.2 结构体定义中的泛型
在结构体中使用泛型的示例如下:
#[derive(Debug)] struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 1, y: 2 }; // Point的两个字段都是整型 println!("{:#?}", integer); let float = Point { x: 0.99, y: 1.99 }; // Point的两个字段都是浮点型 println!("{:#?}", float); }
也可以像如下方式使用:
#[derive(Debug)] struct Point<T, U> { // Point的两个字段可以指定为不同的类型 x: T, y: U, } fn main() { let a = Point { x: 1, y: 2.0 }; println!("{:#?}", a); let b = Point { x: 1, y: 1.99 }; println!("{:#?}", b); }
3.9.3 枚举定义中的泛型
标准库的Option类型就是使用泛型的枚举类型,其定义如下:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
同样的还有Result类型,其定义如下:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
下面再举一个枚举类型中使用泛型的例子:
enum Message<T, U> { Msg1(u32), Msg2(T), Msg3(U), } fn main() { let _msg1: Message<u8, String> = Message::Msg1(1u32); let _msg2:Message<u8, String> = Message::Msg2(2u8); let _msg3:Message<u8, String> = Message::Msg3("hello".to_string()); }
3.9.4 方法定义中的泛型
还可以在方法中使用泛型,例子1: `
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn get_x(&self) -> &T { &self.x } fn get_y(&self) -> &T { &self.y } } fn main() { let p = Point { x: 1, y: 2 }; println!("p.x = {}", p.get_x()); println!("p.y = {}", p.get_y()); }
方法中的泛型不一定和结构体中的一样,示例如下:
struct Point<T, U> { x: T, y: U, } impl<T, U> Point<T, U> { fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c'}; let p3 = p1.mixup(p2); // 对应的T、U分别是整型和浮点型,V、W则分别是字面字符串和字符类型 println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
3.9.5 泛型代码的性能
在Rust中,使用泛型并不会造成程序性能上的损失。因为Rust通过在编译时进行泛型代码的单态化来保证效率(就是在编译时,把泛型换成了具体的类型)。单态化是通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
3.10 Trait
3.10.1 trait基础
trait定义了一组可以被共享的行为,只要实现了trait,就可以在代码中使用这组行为,它类似于其它语言中的接口(interface):
- 可以通过trait以抽象的方式定义共享的行为;
- 可以使用trait bounds指定泛型是任何拥有特定行为的类型。
1. 定义trait
定义trait就是定义一组行为,如下:
#![allow(unused)] fn main() { pub trait GetInformation { fn get_name(&self) -> &String; fn get_age(&self) -> u32; } }
上述代码定义了一个叫做GetInfomation的trait,该trait提供了get_name和get_age方法。
2. 为类型实现trait
2.1 为类型实现trait
代码示例如下:
// 定义trait pub trait GetInformation { fn get_name(&self) -> &String; fn get_age(&self) -> u32; } pub struct Student { pub name: String, pub age: u32, } // 为Student类型实现GetInformation trait impl GetInformation for Student { fn get_name(&self) -> &String { &self.name } fn get_age(&self) -> u32 { self.age } } pub struct Teacher { pub name: String, pub age: u32, } // 为Teacher类型实现GetInformation trait impl GetInformation for Teacher { fn get_name(&self) -> &String { &self.name } fn get_age(&self) -> u32 { self.age } } fn main() { let s = Student { name: "alice".to_string(), age: 18, }; // 可以在类型Student上使用GetInfomation trait中定义的方法 println!("s.name = {:?}, s.age = {:?}", s.get_name(), s.get_age()); let t = Teacher { name: "bob".to_string(), age: 25, }; // 可以类型Teacher使用GetInfomation trait中定义的方法 println!("t.name = {:?}, t.age = {:?}", t.get_name(), t.get_age()); }
2.2 可以在trait定义时提供默认实现
可以在定义trait的时候提供默认的行为,trait的类型可以使用默认的行为,示例如下:
// 定义trait pub trait GetInformation { fn get_name(&self) -> &String; fn get_age(&self) -> u32 { // 在定义trait时就提供默认实现 25u32 } } pub struct Student { pub name: String, pub age: u32, } // 为Student类型实现GetInformation trait impl GetInformation for Student { fn get_name(&self) -> &String { &self.name } // 实现get_age方法,Student不会使用trait定义时的默认实现 fn get_age(&self) -> u32 { self.age } } pub struct Teacher { pub name: String, pub age: u32, } // 为Teacher类型实现GetInformation trait impl GetInformation for Teacher { fn get_name(&self) -> &String { &self.name } // 不实现get_age方法,将使用trait的默认实现 } fn main() { let s = Student { name: "alice".to_string(), age: 18, }; // 可以在类型Student上使用GetInfomation trait中定义的方法 // 输出t.name = "bob", t.age = 25 println!("s.name = {:?}, s.age = {:?}", s.get_name(), s.get_age()); let t = Teacher { name: "bob".to_string(), age: 25, }; // 可以类型Teacher使用GetInfomation trait中定义的方法(t.get_age将使用定义trait时的默认方法) // 输出t.name = "bob", t.age = 25 println!("t.name = {:?}, t.age = {:?}", t.get_name(), t.get_age()); }
如果定义trait时提供了某个方法的默认实现,则:
- 如果为类型实现该trait时,为该类型实现了此方法,则使用自己实现的方法(如上面示例中的Student类型);
- 如果为类型实现该trait时,没有为该类型实现此方法,则该类型使用trait提供的默认实现(如上面的Teacher类型)。
3. trait作为参数
3.1 trait作为参数
trait可以用来参数,示例如下:
// 定义trait pub trait GetInformation { fn get_name(&self) -> &String; fn get_age(&self) -> u32 { 25u32 } } pub struct Student { pub name: String, pub age: u32, } // 为Student类型实现GetInformation trait impl GetInformation for Student { fn get_name(&self) -> &String { &self.name } fn get_age(&self) -> u32 { self.age } } pub struct Teacher { pub name: String, pub age: u32, } // 为Teacher类型实现GetInformation trait impl GetInformation for Teacher { fn get_name(&self) -> &String { &self.name } } // 参数类型必须是实现了GetInfomation trait的类型 pub fn print_information(item: impl GetInformation) { println!("name = {}", item.get_name()); println!("age = {}", item.get_age()); } fn main() { let s = Student { name: "alice".to_string(), age: 18, }; print_information(s); let t = Teacher { name: "bob".to_string(), age: 25, }; print_information(t); }
在上面的例子中,函数pub fn print_information(item: impl GetInformation)的要求参数item必须实现GetInformation trait,否则无法调用该参数。
3.2 使用trait bound语法
上面中的print_information函数还可以写成如下:
#![allow(unused)] fn main() { // 使用trait bound的写法一 pub fn print_information<T: GetInformation>(item: T) { println!("name = {}", item.get_name()); println!("age = {}", item.get_age()); } }
这种写法叫做Trait bound语法,它是Rust中用于指定泛型类型参数所需的trait的一种方式,它还可以使用where关键字写成如下:
#![allow(unused)] fn main() { // 使用trait bound的写法二 pub fn print_information<T>(item: T) where T: GetInformation, { println!("name = {}", item.get_name()); println!("age = {}", item.get_age()); } }
3.3 通过“+”指定多个trait bound
可以要求类型实现多个trait,示例如下:
pub trait GetName { fn get_name(&self) -> &String; } pub trait GetAge { fn get_age(&self) -> u32; } //使用trait bound写法一,类型T必须实现GetName和GetAge trait pub fn print_information1<T: GetName + GetAge>(item: T) { println!("name = {}", item.get_name()); println!("age = {}", item.get_age()); } //使用trait bound写法二,类型T必须实现GetName和GetAge trait pub fn print_information2<T>(item: T) where T: GetName + GetAge, { println!("name = {}", item.get_name()); println!("age = {}", item.get_age()); } #[derive(Clone)] struct Student { name: String, age: u32, } impl GetName for Student { fn get_name(&self) -> &String { &self.name } } impl GetAge for Student { fn get_age(&self) -> u32 { self.age } } fn main() { let s = Student { name: "alice".to_string(), age: 18u32, }; print_information1(s.clone()); print_information1(s); }
在上面的代码中,print_information1和print_information2函数要求其参数类型T必须实现GetName和GetAge两个trait,通过+来进行多个约束的连接。
4. 返回trait的类型
trait类型可以作为函数的返回类型,示例如下:
pub trait GetName { fn get_name(&self) -> &String; } struct Student { name: String, } impl GetName for Student { fn get_name(&self) -> &String { &self.name } } // trait类型作为返回的参数 pub fn produce_item_with_name() -> impl GetName { // 返回一个实现了GetName trait的类型 Student { name: "alice".to_string(), } } fn main() { let s = produce_item_with_name(); println!("name: {:?}", s.get_name()); }
上面代码中,produce_item_with_name函数返回了一个实现了GetName trait的类型。不过需要注意的是,这种方式返回的是单一类型,例如如下的代码就是错误的,无法编译通过:
pub trait GetName { fn get_name(&self) -> &String; } struct Student { name: String, } impl GetName for Student { fn get_name(&self) -> &String { &self.name } } struct Teacher { name: String, } impl GetName for Teacher { fn get_name(&self) -> &String { &self.name } } // 下面的代码将是错误的,无法编译通过,因为在编译时,返回的类型就确定为某一个实现了GetName trait的具体类型了 pub fn produce_item_with_name(is_teacher: bool) -> impl GetName { let result = if is_teacher { Teacher { name: "alice".to_string(), } } else { Student { name: "alice".to_string(), } }; result } fn main() { let s = produce_item_with_name(false); println!("name: {:?}", s.get_name()); }
错误原因分析(非常重要):
上面的代码中的produce_item_with_name函数的定义实际上等价于如下:
pub fn produce_item_with_name<T: GetName>(is_teacher: bool) -> T {
...
result
}
返回的值相当于是一个泛型,这个泛型要求要实现GetName这个trait。回顾泛型的知识,Rust实际上是在编译的时候把泛型换成了具体的类型,所以上面的定义中,T在编译时会变成确定的某个类型(按照上下文,即Student类型或Teacher类型)。所以在编译时,上面的代码可能被翻译成如下两种情况:
#![allow(unused)] fn main() { // 编译时代码将被翻译成如下: pub fn produce_item_with_name(is_teacher: bool) -> Teacher { let result = if is_teacher { Teacher { name: "alice".to_string() } } else { Student { name: "alice".to_string() } }; result } // 也可能翻译成如下: pub fn produce_item_with_name(is_teacher: bool) -> Student { let result = if is_teacher { Teacher { name: "alice".to_string() } } else { Student { name: "alice".to_string() } }; result } }
无论是哪种情况,都是错误的。
那如果需要返回多种实现了trait的类型,则需要使用后续讲解的内容trait对象(3.10.2节)来满足需求。
5. 使用trait bound有条件的实现方法
通过使用带有 trait bound 的泛型参数的impl 块,可以有条件地只为那些实现了特定 trait 的类型实现方法,示例如下:
pub trait GetName { fn get_name(&self) -> &String; } pub trait GetAge { fn get_age(&self) -> u32; } struct PeopleMatchInformation<T, U> { master: T, employee: U, } // 11-15行也可以写成: impl<T: GetName + GetAge, U: GetName + GetAge> PeopleMatchInformation<T, U> impl<T, U> PeopleMatchInformation<T, U> where T: GetName + GetAge, // T和U都必须实现GetName和GetAge trait U: GetName + GetAge, { fn print_all_information(&self) { println!("teacher name = {}", self.master.get_name()); println!("teacher age = {}", self.master.get_age()); println!("student name = {}", self.employee.get_name()); println!("student age = {}", self.employee.get_age()); } } //使用 pub struct Teacher { pub name: String, pub age: u32, } impl GetName for Teacher { fn get_name(&self) -> &String { &(self.name) } } impl GetAge for Teacher { fn get_age(&self) -> u32 { self.age } } pub struct Student { pub name: String, pub age: u32, } impl GetName for Student { fn get_name(&self) -> &String { &(self.name) } } impl GetAge for Student { fn get_age(&self) -> u32 { self.age } } fn main() { let t = Teacher { name: String::from("andy"), age: 32, }; let s = Student { name: String::from("harden"), age: 47, }; let m = PeopleMatchInformation { master: t, employee: s, }; m.print_all_information(); }
上面的代码中,就是为PeopleMatchInformation有条件的实现print_all_information方法。
6. 对任何实现了特定trait的类型有条件的实现trait
在Rust中,另外一种比较常见的trait的用法就是对实现了特定trait的类型有条件的实现trait,示例如下:
// trait定义 pub trait GetName { fn get_name(&self) -> &String; } pub trait PrintName { fn print_name(&self); } // 为实现了GetName trait的类型实现PrintName trait impl<T: GetName> PrintName for T { fn print_name(&self) { println!("name = {}", self.get_name()); } } // 将为Student实现对应的trait pub struct Student { pub name: String, } impl GetName for Student { fn get_name(&self) -> &String { &(self.name) } } fn main() { let s = Student { name: String::from("Andy"), }; s.print_name(); //student实现了GetName trait,因此可是直接使用PrintName trait中的函数print_name }
上面的例子中,就是为实现了GetName trait的类型实现PrintName trait。
3.10.2 trait对象
在上一节中第4点返回trait对象时,提到了produce_item_with_name函数返回的是单一的类型,即在编译时就确定了具体的类型,因此produce_item_with_name无法正确编译。为解决这种问题,Rust中引入了trait对象。
1. 使用trait对象
在Rust中,trait自身不能当作数据类型来使用,但trait 对象可以当作数据类型使用。因此,可以将实现了Trait A的类型B、C、D当作trait A的trait对象来使用。使用trait对象时,基本都是以引用的方式使用,所以使用时通常是引用符号加dyn关键字(即&dyn)。
示例如下:
trait GetName { fn get_name(&self); } struct SchoolMember<'a>(&'a dyn GetName); // 学校成员是GetName trait对象 impl<'a> SchoolMember<'a> { fn print_name(&self) { self.0.get_name(); } } // Student是实现了GetName trait的类型 struct Student { name: String, } impl GetName for Student { fn get_name(&self) { println!("name: {:?}", self.name); } } // Teacher是实现了GetName trait的类型 struct Teacher { name: String, } impl GetName for Teacher { fn get_name(&self) { println!("name: {:?}", self.name); } } fn main() { let alice = Student { name: "alice".to_string(), }; let bob = Teacher { name: "bob".to_string(), }; let sm1 = SchoolMember(&alice); // 把alice作为GetName trait对象传入 sm1.print_name(); let sm2 = SchoolMember(&bob); // 把bob作为GetName trait对象传入 sm2.print_name(); let chalie: &dyn GetName = &Student { name: "chalie".to_string(), }; chalie.get_name(); }
上面代码中,Student和Teacher都实现了GetName trait,因此这两种类型可以当做GetName的trait对象使用。
2. trait对象动态分发的原理
对于trait对象,需要说明如下几点:
- trait 对象大小不固定:这是因为,对于
trait A,类型B可以实现trait A,类型C也可以实现trait A,因此A trait对象的大小是无法确定的(因为可能是B类型也可能是C类型)。 - 使用trait对象时,总是使用它们的引用的方式:
- 虽然trait对象没有固定大小,但它的引用类型的大小固定,它由两个指针组成,因此占两个指针大小。
- 一个指针指向具体类型的实例。
- 另一个指针指向一个虚表vtable,vtable中保存了实例对于可以调用的实现于trait的方法。当调用方法时,直接从vtable中找到方法并调用。
- trait对象的引用方式有多种。例如对于
trait A,其trait对象类型的引用可以是&dyn A、Box<dyn A>、Rc<dyn A>等。
下面通过一段代码来分析一下使用trait对象时内存的布局。代码如下:
trait Vehicle { fn run(&self); } // Car是实现了Vehicle trait的类型 // 只有一个字段表示车牌号 struct Car(u32); impl Vehicle for Car { fn run(&self) { println!("Car {:?} run ... ", self.0); } } // truck是实现了Vehicle trait的类型 // 只有一个字段表示车牌号 struct Truck(u32); impl Vehicle for Truck { fn run(&self) { println!("Truck {:?} run ... ", self.0); } } fn main() { let car = Car(1001); let truck = Truck(1002); let vehicle1: &dyn Vehicle = &car; let vehicle2: &dyn Vehicle = &truck; vehicle1.run(); vehicle2.run(); }
在上面的代码中,vehicle1和vehicle1都是Vehicle trait对象的引用;对于vehicle1来说,trait对象的具体类型是Car;对于vehicle2来说,trait对象的具体类型是Truck。上面代码对应的内存布局如下:
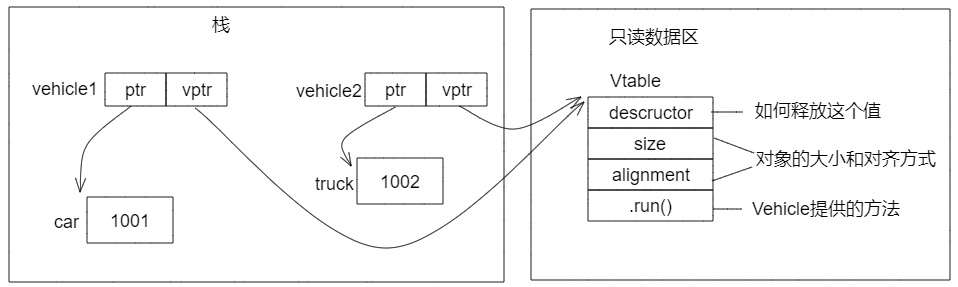
变量car和变量truck分别是Car类型和Truck类型,存储在栈上;vehicle1和vehicle2是Vehicle trait对象的引用,具有两个指针,其中指针ptr指向具体类型的实例,vptr指向虚函数表;虚函数表存储在只读数据区。
更进一步的理解,虚函数表存储在程序的可执行文件中的只读数据段(.rodata)中,这个只读数据段在程序运行时被加载到内存中,因此虚函数表也是只读的。实现trait对象的时候,编译器会在对象的内存布局中添加一个指向虚函数表的指针,这个指针被称为虚函数表指针。在程序运行到vehicle1.run()和vehicle2.run()时,程序通过虚函数表找到对应的函数指针,然后来执行。
3. trait对象要求对象安全
只有对象安全(object safe)的 trait 才可以组成 trait 对象。trait的方法满足以下两条要求才是对象安全的:
- 返回值类型不为
Self; - 方法没有任何泛型类型参数。
分析:
不允许返回
Self,是因为trait对象在产生时,原来的具体的类型会被抹去,Self具体是什么类型不知道,所以编译会报错; 不允许携带泛型参数,是因为Rust用带泛型的类型在编译时会做单态化,而trait对象是运行时才确定,即一个运行时才能确定的东西里又包含一个需要在编译时确定的东西,相互冲突,必然是不行的。
如下代码编译会报错,因为Clone返回的是Self:
#![allow(unused)] fn main() { pub struct Screen { pub components: Vec<Box<dyn Clone>>, } }
3.10.3 常见的trait
Rust 常见的 trait 包括:
std::fmt::Display: 格式化打印用户友好字符串。std::fmt::Debug: 格式化打印调试字符串。std::cmp::PartialEq: 比较值相等。std::cmp::PartialOrd: 比较值顺序。std::cmp::Eq: 类型完全相等关系。std::cmp::Ord: 类型完全顺序关系。std::clone::Clone: 创建类型副本。std::ops::Add: 定义加法操作。std::ops::Mul: 定义乘法操作。std::iter::Iterator: 实现迭代器。
下面分别介绍:
1. std::fmt::Display:
#![allow(unused)] fn main() { use std::fmt; struct Person { name: String, age: u32, } impl fmt::Display for Person { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{} ({} years)", self.name, self.age) } } }
2. std::fmt::Debug:
#![allow(unused)] fn main() { #[derive(Debug)] struct Person { name: String, age: u32, } }
3. std::cmp::PartialEq 和 std::cmp::Eq:
#![allow(unused)] fn main() { #[derive(PartialEq, Eq)] struct Point { x: i32, y: i32, } }
4. std::cmp::PartialOrd 和 std::cmp::Ord:
#![allow(unused)] fn main() { #[derive(PartialOrd, Ord)] struct Point { x: i32, y: i32, } }
5. std::clone::Clone:
#![allow(unused)] fn main() { #[derive(Clone)] struct Point { x: i32, y: i32, } }
6. std::ops::Add:
#![allow(unused)] fn main() { use std::ops::Add; struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } }
7. std::iter::Iterator:
#![allow(unused)] fn main() { struct Counter { count: u32, } impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.count += 1; if self.count < 6 { Some(self.count) } else { None } } } }
3.11 生命周期
Rust中的生命周期是用来管理内存的一种机制。在Rust中,内存的所有权和使用必须是确定的,生命周期就是用来确定内存的使用范围的(说的更具体点,就是确定引用的有效范围):
- 编译器大多数时间能够自动推导生命周期(3.11.1和3.11.2中的例子编译器都能自动推导);
- 在多种类型存在,且编译器无法推导某个引用的生命周期时,需要在代码中显式的标明生命周期。
3.11.1 悬垂指针和生命周期
生命周期的主要目的就是为了避免悬垂引用。考虑如下代码:
fn main() { let r; { let x = 5; r = &x; } println!("r = {}", r); //r为悬垂引用 }
上面代码中,x的有效作用域是从第4行到第6行花括号结束前,即从第6行的花括号后开始,x变为无效,r为x的应用,此时将指向的是一块无效的内存。其内存示意图如下:

3.11.2 借用检查
Rust编译器有一个借用检查器,用它来检查所有的应用的都是有效的,具体的方式为比较变量及其引用的作用域。
1. 示例1如下:
fn main() { let r; //------------------------+-------'a { // | // | let x = 5; //----+---'b | r = &x; // | | } //----+ | println!("r = {}", r); // | //r为悬垂引用 } //---------------------------------------+
对于上面的代码,借用检查器将r的生命周期标注为'a,将x的生命周期标注为'b,然后比较'a和'b的范围,发现'b < 'a,被引用的对象比它的引用者存在的时间还短,然后编译报错。
2. 示例2如下:
fn main() { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {}", r); // | | // --+ | } // ----------+
对于上面的代码,借用检查器将x的生命周期标注为'b,将r的生命周期标注为'a,比较两者范围,发现'b > 'a,被引用对象比它的应用者存在的时间长,编译检查通过。
3.11.3 编译器有时无法自动推导生命周期
如下代码会报错:
fn longest(x: &str, y: &str) -> &str { if x.len() > y.len() { x } else { y } } fn main() { let s1 = String::from("abcd"); let s2 = String::from("ad"); let r = longest(s1.as_str(), s2.as_str()); }
原因为:在存在多个引用时,编译器有时会无法自动推导生命周期,此时就需要程序员在代码中手动去标注,通过为参数标注合适的生命周期来帮助编译器进行借用检查的分析。
3.11.4 标注生命周期
1. 生命周期标注的语法
在开始说明生命周期标注语法前,需要特别明确的是:生命周期标注并不会改变任何引用的实际作用域,标记的生命周期只是为了取悦编译器,让编译器不要难为代码。
生命周期标注的语法为:生命周期参数名称必须以撇号'开头,其名称通常全是小写,类似于泛型,其名称非常短。比较常见的是使用'a作为第一个生命周期标注。生命周期参数标注位于引用符号&之后,并有一个空格来将引用类型与生命周期注解分隔开。
下面为生命周期标注的例子:
&i32 // 引用
&'a i32 // 带有显式生命周期的引用
&'a mut i32 // 带有显式生命周期的可变引用
2. 函数签名中的生命周期
对于3.11.3例子中的函数,显式标注生命周期后的代码如下:
#![allow(unused)] fn main() { fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } } }
上面代码中,对x和y标注生命周期为'a,返回的引用的生命周期也为'a。当调用这个函数时,就要求传入的x和y的生命周期必须是大于等于'a的。当不遵守这个规则的参数传入时,借用检查器就会报错。
3. 深入思考生命周期标注
(1)指定生命周期参数的正确方式依赖函数实现的具体功能。如下代码中将不用标注y的生命周期,因为返回值不依赖于y的生命周期。
#![allow(unused)] fn main() { fn longest<'a>(x: &'a str, y: &str) -> &'a str { x } }
(2)当从函数返回一个引用,返回值的生命周期参数需要与一个参数的生命周期参数相匹配。如果返回的引用没有指向任何一个参数,那么唯一的可能就是它指向一个函数内部创建的值,它将会是一个悬垂引用。如下代码将编译错误:
#![allow(unused)] fn main() { fn longest<'a>(x: &str, y: &str) -> &'a str { let result = String::from("really long string"); result.as_str() //将产生悬垂引用,result在花括号前“}”离开作用域 } }
4. 结构体中的生命周期
结构体中的生命周期标注示例如下:
#[derive(Debug)] struct A<'a> { name: &'a str, // 标注生命周期 } fn main() { let n = String::from("andy"); let a = A { name: &n }; println!("{:#?}", a); }
5. 生命周期省略
在大多数情况下,程序员不用在代码中显式标注生命周期,因为编译器能自动推导。不标注生命周期,我们称之为生命周期省略。例如下面的代码可以正确编译:
#![allow(unused)] fn main() { fn get_s(s: &str) -> &str { s } }
关于生命周期省略有如下说明:
(1)遵守生命周期省略规则的情况下能明确变量的生命周期,则无需明确指定生命周期。函数或者方法的参数的生命周期称为输入生命周期,而返回值的生命周期称为输出生命周期。
(2)编译器采用三条规则判断引用何时不需要生命周期标注,当编译器检查完这三条规则后仍然不能计算出引用的生命周期,则会停止并生成错误。
(3)生命周期标注省略规则适用于fn定义以及impl块定义。
三条判断规则如下:
a、每个引用的参数都有它自己的生命周期参数。例如如下:
一个引用参数的函数,其中有一个生命周期: fn foo<'a>(x: &'a i32)
两个引用参数的函数,则有两个生命周期 :fn foo<'a, 'b>(x: &'a i32, y: &'b i32)以此类推。
b、如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数:
fn foo(x: &i32) -> &i32 等价于 fn foo<'a>(x: &'a i32) -> &'a i32
c、如果方法有多个输入生命周期参数,不过其中之一因为方法的缘故为&self或者&mut self,那么self的生命周期被赋予所有输出生命周期参数。
6. 方法中的生命周期
结构体字段的生命周期必须总是在impl关键字之后声明并在结构体名称之后使用,这些声明周期是结构体类型的一部分,示例如下:
#![allow(unused)] fn main() { struct StuA<'a> { name: &'a str, } impl<'a> StuA<'a> { fn do_something(&self) -> i32 { 3 } } }
下面的例子中,其方法没有显式标注生命周期,因为它符合生命周期省略规则中的第三条规则,代码如下:
#![allow(unused)] fn main() { struct StuA<'a> { name: &'a str, } impl<'a> StuA<'a> { fn do_something2(&self, s: &str) -> &str { self.name //此处符合声明周期注解省略的第三条规则 } } }
7. 静态生命周期
静态生命周期定义方式为:'static,其生命周期存活于整个程序期间。所有的字符字面值都拥有'static生命周期,代码中可以如下来标注:
#![allow(unused)] fn main() { let s: &'static str = "I have a static filetime"; }
8. 结合泛型参数、trait bounds和生命周期的例子
下面示例为在同一函数中指定泛型类型参数、trait bounds 和生命周期:
use std::fmt::Display; fn longest_with_an_announcement<'a, T>(x: &'a str, y: &'a str, ann: T) -> &'a str where T: Display, { println!("Announcement! {}", ann); if x.len() > y.len() { x } else { y } } fn main() { let s1 = String::from("s1"); let s2 = String::from("s2!"); let ann = 128; let r = longest_with_an_announcement(s1.as_str(), s2.as_str(), ann); println!("r = {}", r); println!("Hello, world!"); }
3.12 错误处理
Rust将错误分为两大类:可恢复的和不可恢复的错误。
- 可恢复错误通常代表向用户报告错误和重试操作是合理的情况,例如未找到文件。rust中使用
Result来处理可恢复错误。 - 不可恢复错误是bug的同义词,如尝试访问超过数组结尾的位置。rust中通过
panic!来实现。
3.12.1 用panic!处理不可恢复错误
panic!的使用方式如下:
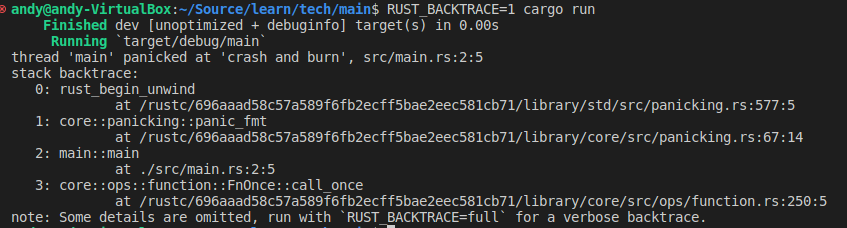
fn main() { panic!("crash and burn"); }
运行该程序会打印如下错误:

运行时添加RUST_BACKTRACE=1,可以打印完整的堆栈,上面的代码运行时加RUST_BACKTRACE=1的结果如下:
3.12.2 用Result处理可恢复错误
1. Result的定义
Rust中使用Result类型处理可恢复错误,其定义如下:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
T和E是泛型类型参数,T代表成功是返回的Ok成员中的数据类型,E代表失败是返回的Err成员中的错误的类型。
2. 使用Result
使用示例如下:
use std::fs::File; fn main() { let f = File::open("hello.txt"); let _r = match f { Ok(file) => { file }, Err(error) => { panic!("Problem opening the file: {:?}", error) } }; }
第3行返回的结果就是一个Result类型,可以使用match匹配Result的具体类型。下面为使用str作为Result<T, E>中的错误E的例子:
// 该函数返回结果为Result<T, E>,其中T为(),E为具有静态生命周期的&str类型 fn produce_error(switch: bool) -> Result<(), &'static str> { if switch { return Err("This is a error"); } Ok(()) } fn main() { let result = produce_error(true); match result { Ok(_) => { println!("There is no error!"); } Err(e) => { println!("Error is: {:?}", e); } } }
3. 失败时直接panic的简写
对于返回Result类型的函数,不用总是使用match去匹配结果,还可以使用简写获取到Result<T, E>中的T类型,不过使用简写时,当Result<T, E>是Err时程序会panic:
3.1 使用unwrap简写:
use std::fs::File; fn main() { let f = File::open("hello.txt").unwrap(); //使用unwrap简写来获取到Result中的T类型, //当hello.txt打开失败时程序会panic }
3.2 使用except简写:
use std::fs::File; fn main() { //使用unwrap简写来获取到Result中的T类型, //当hello.txt打开失败时程序会panic let greeting_file = File::open("hello.txt") .expect("hello.txt should be included in this project"); }
4. 传播错误
除了函数中处理错误外,还可以选择让调用者知道这个错误并决定如何处理,这叫做传播错误。示例如下:
fn produce_error(switch: bool) -> Result<(), &'static str> { if switch { return Err("This is a error"); } Ok(()) } fn transmit_error(flag: bool) -> Result<String, &'static str> { let s = produce_error(flag); match s { Ok(_) => return Ok("Hello".to_string()), Err(e) => return Err(e), } } fn main() { let result = transmit_error(true); match result { Ok(_) => { println!("There is no error!"); } Err(e) => { println!("Error is: {:?}", e); } } }
在上面的代码中,transmit_error中就没有自己处理错误,而是选择将错误传递给外层。
传播错误可以用?进行简写,上面的transmit_error函数代码用简写方式示例如下:
fn produce_error(switch: bool) -> Result<(), &'static str> { if switch { return Err("This is a error"); } Ok(()) } fn transmit_error(flag: bool) -> Result<String, &'static str> { produce_error(flag)?; // 如果调用produce_error函数返回的是Err类型将会直接从此行返回 println!("如果produce_error函数返回的是错误将不会执行到这里"); Ok("Hello".to_string()) } fn main() { // 下面的调用将不会打印"如果produce_error函数返回的是错误将不会执行到这里" let result1 = transmit_error(true); println!("+++++++++++++++++++++++++++++++++++++++++++++++"); // 下面的调用将会打印"如果produce_error函数返回的是错误将不会执行到这里" let result2 = transmit_error(false); ... }
下面是更复杂的简写:
#![allow(unused)] fn main() { use std::io; use std::io::Read; use std::fs::File; fn read_username_from_file() -> Result { let mut s = String::new(); //如果open()失败将直接把“打开失败错误”返回,如果read_to_string失败也将把“读取失败错误”返回 File::open("hello.txt")?.read_to_string(&mut s)?; Ok(s) } }
?运算符被用于返回Result的函数,Result返回的是Err类型,则直接结束将错误传播到上一级。
3.12.3 什么时候使用panic
关于什么时候使用panic,什么使用Result,总结如下:
- 示例、代码原型和测试适合使用panic,使用Result可以使用unwrap、expect的方式;
- 实际项目中应该多使用Result,并且尽量少使用Result的unwrap、expect方式。
3.13 闭包
3.13.1 闭包介绍
闭包是可以保存进变量或者作为参数传递给其它函数的匿名函数。闭包和函数不同的是,闭包允许捕获调用者作用域中的值。下面为使用闭包的简单示例:
fn main() { let use_closure = || { println!("This is a closure"); }; use_closure(); // 此行打印“This is a closure” }
闭包有如下语法格式:
#![allow(unused)] fn main() { fn add_one_v1(x: u32) -> u32 { x + 1 } //函数 let add_one_v2 = |x: u32| -> u32 { x + 1 }; //闭包 let add_one_v3 = |x| { x + 1 }; //自动推导参数类型和返回值类型 let add_one_v4 = |x| x+1; //自动推导参数类型和返回值类型 }
闭包定义会为每个参数和返回类型推导一个具体类型,但是不能推导两次。下面是错误示例:
fn main() { let example_closure = |x| x; let s = example_closure(String::from("hello")); let n = example_closure(5); //报错,尝试推导两次,变成了不同的类型 }
3.13.2 闭包捕获环境
下面的示例展示了闭包捕获环境中的变量:
fn main() { let x = 4; let equal_to_x = |z| z == x; //捕获环境中的值 let y = 4; assert!(equal_to_x(y)); }
闭包可以通过三种方式捕获其环境,对应函数的三种获取参数的方式,分别是获取所有权、可变借用和不可变借用。 这三种捕获值的方式被编码为如下三个trait:
FnOnce:消费从周围作用域捕获变量(即获取捕获变量的所有权),闭包周围的作用域被称为其环境。为了消费捕获到的变量,闭包必须获取其所有权并将其移动进闭包。其名称的Once部分代表了闭包不能多次获取相同变量的所有权。FnMut:获取可变的借用值,所以可以改变其环境。Fn:从其环境获取不可变的借用值。
当创建一个闭包时,Rust会根据其如何使用环境中的变量来推断如何引用环境。由于所有闭包都可以被调用至少一次,因此所有闭包都实现了FnOnce。没有移动被捕获变量的所有权到闭包的闭包也实现了FnMut,而不需要对捕获的变量进行可变访问的闭包则实现了Fn。
下面示例分别给出了实现三种Trait的闭包:
fn call_once(c: impl FnOnce()) { c(); } fn call_mut(c: &mut impl FnMut()) { c(); } fn call_fn(c: impl Fn()) { c(); } fn main() { // 1、闭包use_closure1只实现了FnOnce Trait,只能被调用一次 let s = "Hello".to_string(); let use_closure1 = move || { let s1 = s; println!("s1 = {:?}", s1); }; use_closure1(); // 此行打印“s1 = "Hello"” // println!("s = {:?}", s); // 编译错误:因为s所有权已经被移动闭包中use_closure1中 // use_closure1(); // 编译错误:多次调用use_closure1出错 let s = "Hello".to_string(); let use_closure11 = move || { let s1 = s; println!("s1 = {:?}", s1); }; call_once(use_closure11); // 2、闭包use_closure2只实现了FnOnce Trait和FnMut Trait let mut s = "Hello".to_string(); let mut use_closure2 = || { s.push_str(", world!"); println!("s = {:?}", s); }; use_closure2(); // 此行打印“s = "Hello, world!"” use_closure2(); // 可以多次调用,此行打印“s = "Hello, world!, world!"” call_mut(&mut use_closure2); call_once(use_closure2); // 3、闭包use_closure3实现了FnOnce Trait、FnMut Trait和Fn Trait let s = "Hello".to_string(); let mut use_closure3 = || { println!("s = {:?}", s); }; use_closure3(); // 此行打印“s = "Hello"” use_closure3(); // 可以多次调用,此行打印“s = "Hello!"” call_fn(use_closure3); call_mut(&mut use_closure3); call_once(use_closure3); }
3.13.3 作为参数和返回值
1. 函数指针
函数指针的使用可以让函数作为另一个函数的参数。函数的类型是fn,fn被称为函数指针。指定参数为函数指针的语法类似于闭包。
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { //第一个参数为函数指针 f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {}", answer); }
函数指针实现了闭包的三个trait(Fn、FnMut 和 FnOnce),函数指针作为参数的地方也可以传入闭包。
2. 闭包作为参数和返回值
基于上面的1的知识可知,闭包可以作为参数,同样也可以作为返回值,闭包作为参数的示例如下:
fn wrapper_func<T>(t: T, v: i32) -> i32 where T: Fn(i32) -> i32, { t(v) } fn func(v: i32) -> i32 { v + 1 } fn main() { let a = wrapper_func(|x| x + 1, 1); // 闭包作为参数 println!("a = {}", a); let b = wrapper_func(func, 1); // 函数作为参数 println!("b = {}", b); }
闭包作为返回值的示例如下:
fn returns_closure() -> Box<dyn Fn(i32) -> i32> { // 返回的是trait对象 Box::new(|x| x + 1) } fn main() { let c = returns_closure(); println!("r = {}", c(1)); //等价于println!("r = {}", (*c)(1)); }
需要注意的是,函数定义时返回的是Box包含的trait对象,因为编译器在编译时需要知道返回值的大小。所以对于下面两种returns_closure函数定义,编译器将报错:
#![allow(unused)] fn main() { // 错误方式一 fn returns_closure() -> dyn Fn(i32) -> i32 { |x| x + 1 } // 错误方式二 fn returns_closure() -> Fn(i32) -> i32 { |x| x + 1 } }
3. 闭包和泛型
闭包还可以和泛型结合在一起使用,示例如下:
// T 要求实现Fn fn returns_closure1<T>(f: T) -> T where T: Fn(i32) -> i32, { f } // T 要求实现FnMut fn returns_closure2<T>(f: T) -> T where T: FnMut(), { f } // T 要求实现FnOnce fn returns_closure3<T>(f: T) -> T where T: FnOnce(), { f } fn main() { let closure1 = |x| x + 1; let c = returns_closure1(closure1); println!("r = {}", c(1)); // T 实现了FnMut、FnOnce let mut s = "Hello".to_string(); let closure2 = || { s.push_str(", world!"); }; let mut c = returns_closure2(closure2); c(); println!("s: {:?}", s); let s = "Hello".to_string(); let closure3 = move || { let s1 = s; println!("s = {:?}", s1); }; let c = returns_closure3(closure3); c(); }
3.13.4 闭包背后的原理
Rust中的闭包是通过一个特殊的结构体实现的。具体来说,每个闭包都是一个结构体对象,其中包含了闭包的代码和环境中捕获的变量。这个结构体对象实现了一个或多个trait,以便可以像函数一样使用它。
当定义一个闭包时,Rust编译器会根据闭包的代码和捕获的变量生成一个结构体类型,这个结构体类型实现了对应的trait。例如,以下代码定义了一个闭包add_x并调用它:
fn main() { let x = 10; let add_x = |y| x + y; // 闭包 println!("{}", add_x(5)); // 调用闭包 }
在编译时,Rust编译器会将这个闭包add_x转换为如下的结构体类型:
#![allow(unused)] fn main() { struct Closure<'a> { x: i32, } impl<'a> FnOnce<(i32,)> for Closure<'a> { type Output = i32; fn call_once(self, args: (i32,)) -> i32 { self.x + args.0 } } impl<'a> FnMut<(i32,)> for Closure<'a> { fn call_mut(&mut self, args: (i32,)) -> i32 { self.x + args.0 } } impl<'a> Fn<(i32,)> for Closure<'a> { extern "rust-call" fn call(&self, args: (i32,)) -> i32 { self.x + args.0 } } }
当闭包被调用时,它实际上是通过调用结构体的方法来执行的。所以调用闭包的代码就变成了如下:
fn main() { let x = 10; let mut add_x = Closure { x, y: 0 }; println!("{}", add_x(5)); }
3.14 迭代器
通过迭代器模式可以对一个集合的项进行某些处理。迭代器(iterator)负责遍历集合中的每一项和决定何时结束处理的逻辑。当使用迭代器时,无需重新实现这些逻辑。迭代器是惰性的,即在调用方法使用迭代器之前,它不会有任何效果。
3.14.1 Iterator trait
迭代器都实现了Iterator trait,该trait定义在Rust标准库中,如下:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; ... } }
type Item和Self::Item这种用法叫做定义trait的关联类型。Item类型将是迭代器返回元素的类型,next方法是Iterator实现者被要求定义的唯一方法,next一次返回一个元素,当迭代器结束,则返回None。
示例如下:
struct Counter { count: u32, } impl Counter { fn new() -> Counter { Counter { count: 0 } } } impl Iterator for Counter { //Counter实现Iterator trait,是一个迭代器 type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.count += 1; if self.count < 6 { Some(self.count) } else { None } } } fn main() { let mut counter = Counter::new(); println!("{:?}", counter.next()); println!("{:?}", counter.next()); println!("{:?}", counter.next()); println!("{:?}", counter.next()); println!("{:?}", counter.next()); let mut counter1 = Counter::new(); for item in counter1 { // for循环是迭代器的语法糖,自动对迭代器进行迭代 println!(" item = {}", item); } }
3.14.2 IntoIterator trait
如果一个类型实现IntoIterator trait,就可以为该类型创建迭代器(换句话说就是可以把该类型转换为迭代器),进而能调用迭代器对应的方法。
通常有三种创建迭代器的方法,分别如下:
iter()方法,创建一个在&T上进行迭代的迭代器,即在集合自身引用上迭代的迭代器;iter_mut()方法,创建一个在&mut T上进行迭代的迭代器,即集合自身可变引用上迭代的迭代器;into_iter()方法,创建一个在T上迭代的迭代器,即移动了自身所有权的迭代器。
Vec就实现了IntoIterator trait,所以它可以转换为迭代器,使用示例如下:
fn main() { // 1、----使用iter()示例------ let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); //得到迭代器 //iter()产生的迭代器,使用迭代器不会改变每个元素,只是对每个元素的引用 for val in v1_iter { println!("Got: {}", val); } println!("v1: {:?}", v1); // 2、----使用iter_mut()示例------ let mut v2 = vec![1, 2, 3]; let v2_iter = v2.iter_mut(); // 得到迭代器 //iter_mut()产生的迭代器,使用迭代器可能会改变每个元素 for val in v2_iter { if *val > 1 { *val = 1; } println!("Got: {}", val); } println!("v2: {:?}", v2); // 3、----使用into_iter()示例------ let v3 = vec![1, 2, 3]; let v3_iter = v3.into_iter(); // 得到迭代器 //into_iter()产生的迭代器,使用迭代器后无法再使用原来的集合v3 for val in v3_iter { println!("Got: {}", val); } // println!("v3: {:?}", v3); //此行将打开编译会出错 }
IntoIterator trait和Iterator trait的关系:
Iterator就是迭代器的trait,实现了该trait就是迭代器;IntoIterator trait则是表示可以转换为迭代器,如果一个类型实现了IntoIterator trait,则它可以调用iter()、iter_mut()、into_iter()转换为迭代器。
3.14.3 迭代器消费器
迭代器通过next方法来消费一个项。下面为直接使用next方法的示例:
fn main() { let v1 = vec![1, 2, 3]; let mut v1_iter = v1.iter(); if let Some(v) = v1_iter.next() { println!("{}", v); //1 } }
Iterator trait有一系列由标准库提供的默认实现的方法,有些方法调用了next方法,这些调用next方法的方法被称为消费适配器。
下面是一个使用消费是适配器sum方法的例子:
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); let total: i32 = v1_iter.sum(); //调用消费适配器sum来求和 println!("total = {:?}", total); }
3.14.4 迭代器适配器
Iterator trait中定义了一类方法,可以把将当前迭代器变为不同类型的迭代器,这类方法就是迭代器适配器。
fn main() { let v1: Vec<i32> = vec![1, 2, 3]; //下面的 v1.iter().map(|x| x + 1) 创建了一个新的迭代器 let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); //v2 = vec![2, 3, 4] println!("total = {:?}", v1); println!("total = {:?}", v2); }
下面的代码也是使用迭代器适配器:
fn main() { let v1: Vec<i32> = vec![1, 11, 5, 34, 2, 10]; let v2: Vec<i32> = v1.into_iter().filter(|x| *x > 5).collect(); // println!("v1 = {:?}", v1); // 此行打开将报错,因为上面创建的迭代器是将原来的所有权移到新的迭代器中了 println!("v2 = {:?}", v2); }
3.14.5 自定义迭代器
自定义迭代器示例如下:
struct Counter { count: u32, } impl Counter { fn new() -> Counter { Counter { count: 0 } } } impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.count += 1; if self.count < 6 { Some(self.count) } else { None } } } fn main() { let counter = Counter::new(); for item in counter { // 实现Iterator trait println!(" item = {}", item); } }
3.15 常见Collections
- 3.15.1 Vector(向量)
- 3.15.2 String(字符串)
- 3.15.3 HashMap(哈希映射)
- 3.15.4 HashSet(哈希集合)
- 3.15.5 LinkedList(链表)
- 3.15.6 BTreeMap(B 树映射)
- 3.15.7 BTreeSet(B 树集合)
3.15.1 Vector(向量)
Rust 中的 Vector(向量)是一个动态的、可增长的数组,它可以存储一系列相同类型的元素。向量在连续的内存空间中存储元素,这使得访问和修改元素非常快。以下是有关 Rust 向量的一些详细信息:
1. 创建 Vector:
可以使用 Vec<T> 类型创建一个向量,其中 T 是存储在向量中的元素的类型。要创建一个新的空向量,可以使用 Vec::new() 方法。
#![allow(unused)] fn main() { let mut vec = Vec::new(); }
或者,可以使用宏 vec![] 初始化一个包含初始值的向量:
#![allow(unused)] fn main() { let vec = vec![1, 2, 3, 4, 5]; }
2. 添加元素:
可以使用 push() 方法向向量的末尾添加一个元素。
#![allow(unused)] fn main() { vec.push(6); }
3.访问元素:
可以通过索引访问向量中的元素,类似于数组。请注意,尝试访问无效索引可能导致运行时错误。
#![allow(unused)] fn main() { let first = vec[0]; // 访问向量中的第一个元素 }
或者,可以使用 get() 方法安全地访问元素,它返回一个 Option 类型。如果指定的索引有效,则返回 Some(element),否则返回 None。
#![allow(unused)] fn main() { let first = vec.get(0); // 返回 Option<&T> }
4. 遍历元素:
可以使用 for 循环遍历向量中的所有元素。
#![allow(unused)] fn main() { for element in &vec { println!("Element: {}", element); } }
5. 删除元素:
可以使用 remove() 方法删除向量中指定索引处的元素。此操作将删除元素并将后续元素向前移动。
#![allow(unused)] fn main() { vec.remove(0); // 删除向量中的第一个元素 }
6. Vector 的容量和长度:
向量的长度是其中的元素数量,而容量是为这些元素分配的内存空间。向量会根据需要自动增长,但当长度超过容量时,它需要重新分配内存并复制元素到新内存区域。可以使用 len() 获取向量的长度,使用 capacity() 获取容量,还可以使用 shrink_to_fit() 方法减小容量以匹配当前长度。
7. 切片:
切片是对向量一部分元素的引用,可以用作轻量级的视图。要创建切片,可以使用范围语法:
#![allow(unused)] fn main() { let slice = &vec[1..4]; // 创建一个包含索引 1 到 3(包括 1,不包括 4)的元素的切片 }
向量是 Rust 中使用非常广泛的集合类型,因为它提供了灵活性、性能和安全性。
3.14.2 String(字符串)
Rust 中的 String(字符串)是一个可增长的、UTF-8 编码的字符串类型。它可以存储和处理文本数据。这里是关于 Rust 字符串的一些详细信息:
1. 创建 String:
可以使用 String::new() 创建一个新的空字符串,或者使用 String::from() 从字符串字面量创建字符串。
#![allow(unused)] fn main() { let mut s = String::new(); let s = String::from("hello"); }
还可以使用 to_string() 方法将基本类型转换为字符串。
#![allow(unused)] fn main() { let num = 42; let s = num.to_string(); }
2. 字符串长度:
字符串的长度是其 UTF-8 编码的字节的数量,而不是 Unicode 字符的数量。可以使用 len() 方法获取字符串的长度。
#![allow(unused)] fn main() { let len = s.len(); }
3. 字符串拼接:
有多种方法可以将字符串拼接在一起。例如,可以使用 + 运算符或 format! 宏。
#![allow(unused)] fn main() { let s1 = String::from("hello"); let s2 = String::from("world"); let s3 = s1 + " " + &s2; }
或者使用 push_str() 方法将字符串附加到现有字符串。
#![allow(unused)] fn main() { let mut s = String::from("hello"); s.push_str(" world"); }
4. 访问字符:
由于 Rust 字符串是 UTF-8 编码的,不能直接使用索引访问单个字符。但是,可以使用迭代器遍历字符串中的字符。
#![allow(unused)] fn main() { for c in s.chars() { println!("{}", c); } }
还可以使用 bytes() 方法遍历字节,或者使用 char_indices() 方法获取字符及其对应的字节索引。
5.字符串切片:
可以使用范围语法创建字符串的切片,它表示原始字符串中一部分的引用。需要确保范围边界位于有效的 UTF-8 字符边界上,否则将导致运行时错误。
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..4]; // 获取字符串前 4 个字节的切片 }
6. 修改字符串:
可以使用 push() 方法将一个字符添加到字符串的末尾,或者使用 insert()
方法将字符插入指定的字节位置。
#![allow(unused)] fn main() { let mut s = String::from("hello"); s.push('!'); s.insert(5, ','); }
注意,字符串插入操作可能需要 O(n) 时间,其中 n 是插入位置之后的字节数。
7. 删除字符串中的字符:
可以使用 pop() 方法删除并返回字符串末尾的字符,或者使用 remove() 方法删除并返回指定字节位置处的字符。
#![allow(unused)] fn main() { let mut s = String::from("hello"); s.pop(); s.remove(0); }
Rust 的字符串处理非常关注编码安全性和性能,因此,与其他编程语言相比,某些操作可能有所不同。然而,这使得 Rust 能够提供安全、高效的字符串操作。
3.15.3 HashMap(哈希映射)
Rust 中的 HashMap(哈希映射)是一个基于键值对的无序集合,它提供了高效的查找、插入和删除操作。HashMap 使用哈希函数将键映射到相应的存储桶,这使得大部分操作具有 O(1) 的平均时间复杂度。以下是有关 Rust HashMap 的一些详细信息:
1. 创建 HashMap:
要创建一个新的空 HashMap,可以使用 HashMap::new() 方法。需要导入 std::collections::HashMap 模块以使用 HashMap。
#![allow(unused)] fn main() { use std::collections::HashMap; let mut map = HashMap::new(); }
2. 插入键值对:
可以使用 insert() 方法向 HashMap 中添加键值对。如果使用相同的键插入新值,旧值将被替换。
#![allow(unused)] fn main() { map.insert("one", 1); map.insert("two", 2); }
3. 访问值:
可以使用 get() 方法根据键查找值。此方法返回一个 Option<&V> 类型,如果找到键,则返回 Some(&value),否则返回 None。
#![allow(unused)] fn main() { let value = map.get("one"); // 返回 Option<&V> }
还可以使用 get_mut() 方法获取可变引用。
4. 遍历键值对:
可以使用 for 循环遍历 HashMap 中的所有键值对。
#![allow(unused)] fn main() { for (key, value) in &map { println!("{}: {}", key, value); } }
5. 删除键值对:
可以使用 remove() 方法根据键删除键值对。此方法返回一个 Option<V> 类型,如果找到并删除了键值对,则返回 Some(value),否则返回 None。
#![allow(unused)] fn main() { map.remove("one"); // 删除键为 "one" 的键值对 }
6. 检查键是否存在:
可以使用 contains_key() 方法检查 HashMap 中是否存在指定的键。
#![allow(unused)] fn main() { let has_key = map.contains_key("one"); // 返回布尔值 }
7. 更新值:
可以使用 entry() 方法与 or_insert() 方法结合,更新 HashMap 中的值或插入新值。
#![allow(unused)] fn main() { *map.entry("three").or_insert(3) += 1; }
8. HashMap 的容量和长度:
可以使用 len() 方法获取 HashMap 中的键值对数量,使用 capacity() 方法获取容量。还可以使用 shrink_to_fit() 方法减小容量以匹配当前长度。
9. 默认哈希器:
Rust 的 HashMap 默认使用一个加密安全的哈希函数(SipHash),它在防止哈希碰撞攻击方面表现良好,但可能不如其他哈希函数快。可以通过为 HashMap 类型提供自定义的哈希器来改变默认行为。
#![allow(unused)] fn main() { use std::collections::HashMap; use std::hash::BuildHasherDefault; use twox_hash::XxHash64; type FastHashMap<K, V> = HashMap<K, V, BuildHasherDefault<XxHash64>>; let mut map: FastHashMap<&str, i32> = FastHashMap::default(); map.insert("one", 1); map.insert("two", 2); }
在这个例子中,我们使用了 twox_hash 库中的 XxHash64 哈希函数,它通常比默认的 SipHash 更快。请注意,使用自定义哈希函数可能会降低安全性,因此要确保在明确了解潜在风险的情况下进行更改。
10. 合并两个 HashMap:
可以使用 extend() 方法将另一个 HashMap 的键值对添加到当前 HashMap 中。如果存在重复的键,目标 HashMap 中的值将被源 HashMap 中的值覆盖。
#![allow(unused)] fn main() { let mut map1 = HashMap::new(); map1.insert("one", 1); map1.insert("two", 2); let mut map2 = HashMap::new(); map2.insert("two", 22); map2.insert("three", 3); map1.extend(map2); // 将 map2 中的键值对添加到 map1 }
这样,map1 将包含键值对 "one" -> 1, "two" -> 22 和 "three" -> 3。
总之,Rust 中的 HashMap 是一个功能丰富且性能优越的键值对集合,非常适合在需要快速查找和修改操作的场景中使用。
3.15.4 HashSet(哈希集合)
Rust 中的 HashSet(哈希集合)是一种无序的、不含重复元素的集合。它使用哈希函数将元素映射到相应的存储桶,这使得大部分操作具有 O(1) 的平均时间复杂度。以下是有关 Rust HashSet 的一些详细信息:
1. 创建 HashSet:
要创建一个新的空 HashSet,可以使用 HashSet::new() 方法。需要导入 std::collections::HashSet 模块以使用 HashSet。
#![allow(unused)] fn main() { use std::collections::HashSet; let mut set = HashSet::new(); }
2. 添加元素:
可以使用 insert() 方法向 HashSet 中添加元素。如果元素已存在,则此方法将返回 false,否则返回 true。
#![allow(unused)] fn main() { set.insert(1); set.insert(2); set.insert(3); }
3. 检查元素是否存在:
可以使用 contains() 方法检查 HashSet 中是否存在指定的元素。
#![allow(unused)] fn main() { let contains = set.contains(&1); // 返回布尔值 }
4. 删除元素:
可以使用 remove() 方法删除 HashSet 中的元素。此方法返回一个 bool 类型,如果找到并删除了元素,则返回 true,否则返回 false。
#![allow(unused)] fn main() { set.remove(&1); // 删除元素 1 }
5. 遍历元素:
可以使用 for 循环遍历 HashSet 中的所有元素。
#![allow(unused)] fn main() { for element in &set { println!("{}", element); } }
6. HashSet 的长度:
可以使用 len() 方法获取 HashSet 中的元素数量。还可以使用 is_empty() 方法检查 HashSet 是否为空。
7. 集合操作:
HashSet 支持一些基本的集合操作,如并集、交集、差集和对称差集。
-
并集(union):返回一个新的 HashSet,包含两个集合中的所有元素。
#![allow(unused)] fn main() { let set1: HashSet<_> = [1, 2, 3].iter().cloned().collect(); let set2: HashSet<_> = [3, 4, 5].iter().cloned().collect(); let union: HashSet<_> = set1.union(&set2).cloned().collect(); } -
交集(intersection):返回一个新的 HashSet,包含两个集合中共有的元素。
#![allow(unused)] fn main() { let intersection: HashSet<_> = set1.intersection(&set2).cloned().collect(); } -
差集(difference):返回一个新的 HashSet,包含第一个集合中存在但第二个集合中不存在的元素。
#![allow(unused)] fn main() { let difference: HashSet<_> = set1.difference(&set2).cloned().collect(); } -
对称差集(symmetric_difference):返回一个新的 HashSet,包含两个集合中唯一的元素(也就是只存在于一个集合中的元素)。
#![allow(unused)] fn main() { let symmetric_difference: HashSet<_> = set1.symmetric_difference(&set2).cloned().collect(); }
8. 清空 HashSet:
可以使用 clear() 方法删除 HashSet 中的所有元素。
#![allow(unused)] fn main() { set.clear(); // 清空 HashSet }
总的来说,Rust 中的 HashSet提供了一种高效且易于使用的无序集合实现,适用于需要快速查找、添加和删除操作的场景。由于 HashSet 的底层实现基于哈希表,它能够在大部分情况下为这些操作提供 O(1) 的平均时间复杂度。
与 HashMap 类似,Rust 的 HashSet 默认使用一个加密安全的哈希函数(SipHash),以防止哈希碰撞攻击。如果需要更高的性能,可以考虑使用自定义哈希器,但要确保在明确了解潜在风险的情况下进行更改。这是一个使用自定义哈希器的例子 :
#![allow(unused)] fn main() { use std::collections::HashSet; use std::hash::BuildHasherDefault; use twox_hash::XxHash64; type FastHashSet<T> = HashSet<T, BuildHasherDefault<XxHash64>>; let mut set: FastHashSet<i32> = FastHashSet::default(); set.insert(1); set.insert(2); }
在这个例子中,我们使用了 twox_hash 库中的 XxHash64 哈希函数,它通常比默认的 SipHash 更快。
3.15.5 LinkedList(链表)
Rust 中的 LinkedList(链表)是一种线性数据结构,它由一系列相互连接的节点组成。每个节点都包含一个元素和指向前一个节点和后一个节点的指针。这是有关 Rust LinkedList 的一些详细信息:
1. 创建 LinkedList:
要创建一个新的空 LinkedList,可以使用 LinkedList::new() 方法。需要导入 std::collections::LinkedList 模块以使用 LinkedList。
#![allow(unused)] fn main() { use std::collections::LinkedList; let mut list = LinkedList::new(); }
2. 添加元素:
可以使用 push_front() 和 push_back() 方法将元素添加到链表的开头和结尾。
#![allow(unused)] fn main() { list.push_front(1); list.push_back(2); }
3. 访问元素:
可以使用 front() 和 back() 方法分别访问链表的第一个和最后一个元素。这些方法返回一个 Option<&T> 类型,如果链表不为空,则返回 Some(&element),否则返回 None。
#![allow(unused)] fn main() { let first_element = list.front(); // 返回 Option<&T> let last_element = list.back(); // 返回 Option<&T> }
还可以使用 front_mut() 和 back_mut() 方法获取可变引用。
4. 删除元素:
可以使用 pop_front() 和 pop_back() 方法分别删除并返回链表的第一个和最后一个元素。这些方法返回一个 Option<T> 类型,如果链表不为空且成功删除元素,则返回 Some(element),否则返回 None。
#![allow(unused)] fn main() { list.pop_front(); // 删除并返回第一个元素 list.pop_back(); // 删除并返回最后一个元素 }
5. 遍历元素:
可以使用 iter() 方法遍历链表中的所有元素。iter_mut() 方法可用于遍历可变引用。
#![allow(unused)] fn main() { for element in list.iter() { println!("{}", element); } }
6. 链表长度:
可以使用 len() 方法获取链表中的元素数量。还可以使用 is_empty() 方法检查链表是否为空。
7. 清空链表:
可以使用 clear() 方法删除链表中的所有元素。
#![allow(unused)] fn main() { list.clear(); // 清空链表 }
8. 分割链表:
可以使用 split_off() 方法在指定索引处分割链表。此操作会将链表分成两个链表,前一个链表包含指定索引之前的元素,后一个链表包含指定索引及之后的元素。
#![allow(unused)] fn main() { let mut list1 = LinkedList::new(); list1.push_back(1); list1.push_back(2); list1.push_back(3); let list2 = list1.split_off(1); }
这样,list1 将包含元素 1,而 list2 将包含元素 2 和 3。
总之,Rust 中的 LinkedList 提供了一种基于节点的线性数据结构,它适用于需要快速插入和删除操作的场景。然而,对于许多其他用途,如随机访问和查找操作,链表通常比数组或向量(Vector)等基于连续内存的数据结构性能差。这是因为链表的元素在内存中是分散存储的,这会导致较差的缓存局部性(cache locality)。而连续内存数据结构在许多情况下可以更有效地利用 CPU 缓存,从而提高性能。
当考虑使用链表时,务必评估其适用性,并与其他数据结构(如 Vector)进行比较。在某些情况下,链表可能是一个很好的选择,特别是当插入和删除操作的性能比访问和查找操作更重要时。然而,在许多场景中,使用基于连续内存的数据结构会带来更好的性能和更简单的代码。
3.15.6 BTreeMap(B 树映射)
Rust 中的 BTreeMap(B 树映射)是一种自平衡的有序映射数据结构,它以 B 树的形式存储键值对。BTreeMap 具有对数级的时间复杂度,这使得它在需要维护键的顺序时非常有效。以下是有关 Rust BTreeMap 的一些详细信息:
1. 创建 BTreeMap:
要创建一个新的空 BTreeMap,可以使用 BTreeMap::new() 方法。需要导入 std::collections::BTreeMap 模块以使用 BTreeMap。
#![allow(unused)] fn main() { use std::collections::BTreeMap; let mut map = BTreeMap::new(); }
2. 添加元素:
可以使用 insert() 方法向 BTreeMap 中添加键值对。如果键已存在,则此方法将返回 Some(old_value),否则返回 None。
#![allow(unused)] fn main() { map.insert("one", 1); map.insert("two", 2); map.insert("three", 3); }
3. 访问元素:
可以使用 get() 方法根据键查找对应的值。此方法返回一个 Option<&V> 类型,如果找到键,则返回 Some(&value),否则返回 None。
#![allow(unused)] fn main() { let value = map.get("one"); // 返回 Option<&V> }
还可以使用 get_mut() 方法获取可变引用。
4. 删除元素:
可以使用remove() 方法删除 BTreeMap 中的键值对。此方法返回一个 Option<V> 类型,如果找到并删除了键值对,则返回 Some(value),否则返回 None。
#![allow(unused)] fn main() { map.remove("one"); // 删除键为 "one" 的键值对 }
5. 遍历元素:
可以使用 iter() 方法遍历 BTreeMap 中的所有键值对。遍历顺序按键的顺序进行。iter_mut() 方法可用于遍历可变引用。
#![allow(unused)] fn main() { for (key, value) in map.iter() { println!("{}: {}", key, value); } }
6. BTreeMap 的长度:
可以使用 len() 方法获取 BTreeMap 中的键值对数量。还可以使用 is_empty() 方法检查 BTreeMap 是否为空。
7. 最小和最大键:
可以使用 first_key_value() 和 last_key_value() 方法分别获取 BTreeMap 中具有最小和最大键的键值对。这些方法返回一个 Option<(&K, &V)> 类型,如果找到键值对,则返回 Some((&key, &value)),否则返回 None。
#![allow(unused)] fn main() { let min_key_value = map.first_key_value(); // 返回 Option<(&K, &V)> let max_key_value = map.last_key_value(); // 返回 Option<(&K, &V)> }
8. 范围查询:
可以使用 range() 方法查询 BTreeMap 中某个范围内的键值对。例如,可以查询所有键大于等于 "one" 且小于等于 "three" 的键值对:
#![allow(unused)] fn main() { for (key, value) in map.range("one".."three") { println!("{}: {}", key, value); } }
3.15.7 BTreeSet(B 树集合)
Rust 中的 BTreeSet(B 树集合)是一种自平衡的有序集合数据结构,它以 B 树的形式存储元素。BTreeSet 具有对数级的时间复杂度,这使得它在需要维护元素顺序时非常有效。以下是有关 Rust BTreeSet 的一些详细信息:
1. 创建 BTreeSet:
要创建一个新的空 BTreeSet,可以使用 BTreeSet::new() 方法。需要导入 std::collections::BTreeSet 模块以使用 BTreeSet。
#![allow(unused)] fn main() { use std::collections::BTreeSet; let mut set = BTreeSet::new(); }
2. 添加元素:
可以使用 insert() 方法向 BTreeSet 中添加元素。如果元素已存在,则此方法将返回 false,否则返回 true。
#![allow(unused)] fn main() { set.insert(1); set.insert(2); set.insert(3); }
3. 检查元素是否存在:
可以使用 contains() 方法检查 BTreeSet 中是否存在指定的元素。
#![allow(unused)] fn main() { let contains = set.contains(&1); // 返回布尔值 }
4. 删除元素:
可以使用 remove() 方法删除 BTreeSet 中的元素。此方法返回一个 bool 类型,如果找到并删除了元素,则返回 true,否则返回 false。
#![allow(unused)] fn main() { set.remove(&1); // 删除元素 1 }
5. 遍历元素:
可以使用 for 循环遍历 BTreeSet 中的所有元素。遍历顺序按元素的顺序进行。
#![allow(unused)] fn main() { for element in &set { println!("{}", element); } }
6. BTreeSet 的长度:
可以使用 len() 方法获取 BTreeSet 中的元素数量。还可以使用 is_empty() 方法检查 BTreeSet 是否为空。
7. 集合操作:
BTreeSet 支持一些基本的集合操作,如并集、交集、差集和对称差集。
-
并集(union):返回一个新的 BTreeSet,包含两个集合中的所有元素。
#![allow(unused)] fn main() { let set1: BTreeSet<_> = [1, 2, 3].iter().cloned().collect(); let set2: BTreeSet<_> = [3, 4, 5].iter().cloned().collect(); let union: BTreeSet<_> = set1.union(&set2).cloned().collect(); } -
交集(intersection):返回一个新的 BTreeSet,包含两个集合中共有的元素。
#![allow(unused)] fn main() { let intersection: BTreeSet<_> = set1.intersection(&set2).cloned().collect(); } -
差集(difference):返回一个新的 BTreeSet,包含第一个集合中存在但第二个集合中不存在的元素。
#![allow(unused)] fn main() { let difference: BTreeSet<_> = set1.difference(&set2).cloned().collect(); } -
对称差集(symmetric_difference):返回一个新的 BTreeSet,包含两个集合中唯一的元素(也就是只存在于一个集合中的元素)
#![allow(unused)] fn main() { let symmetric_difference: BTreeSet<_> = set1.symmetric_difference(&set2).cloned().collect(); }
8. 最小和最大元素:
可以使用 first() 和 last() 方法分别获取 BTreeSet 中的最小和最大元素。这些方法返回一个 Option<&T> 类型,如果找到元素,则返回 Some(&element),否则返回 None。
#![allow(unused)] fn main() { let min_element = set.first(); // 返回 Option<&T> let max_element = set.last(); // 返回 Option<&T> }
9. 范围查询:
可以使用 range() 方法查询 BTreeSet 中某个范围内的元素。例如,可以查询所有大于等于 1 且小于等于 3 的元素:
#![allow(unused)] fn main() { for element in set.range(1..=3) { println!("{}", element); } }
10. 清空 BTreeSet:
可以使用 clear() 方法删除 BTreeSet 中的所有元素。
#![allow(unused)] fn main() { set.clear(); // 清空 BTreeSet }
总之,Rust 中的 BTreeSet 提供了一种有序集合数据结构,适用于需要维护元素顺序以及执行集合操作的场景。与 BTreeMap 类似,BTreeSet 具有对数级的时间复杂度,这使得它在需要维护元素顺序时非常有效。然而,在需要快速查找、添加和删除操作的场景中,使用基于哈希表的数据结构(如 HashSet)可能更适合。
3.16 智能指针
- 3.16.1 智能指针介绍
- 3.16.2 Box智能指针
- 3.16.3 Deref trait
- 3.16.4 Drop trait
- 3.16.5 Rc智能指针
- 3.16.6 RefCell智能指针
- 3.16.7 引用循环、内存泄露、Weak智能指针
3.16.1 智能指针介绍
指针是一个包含了内存地址的变量,该内存地址引用或者指向了另外的数据,其在内存中的示意图如下:
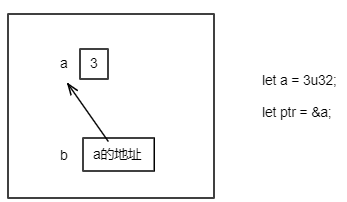
智能指针是一类数据结构,其表现类似于指针,但是相对于指针来说,还拥有额外的元数据。普通引用和智能指针的另一个非常重要的区别就是:引用只是只借用数据的指针,而智能指针则是拥有它们指向的数据。
智能指针是一个胖指针,但是胖指针不一定是智能指针。前面章节介绍过的String类型就是一个智能指针,而它对应的切片引用&str则只仅仅是一个胖指针,区别就在于String类型拥有对数据的所有权,而&str没有。两者在内存中的示意图如下:
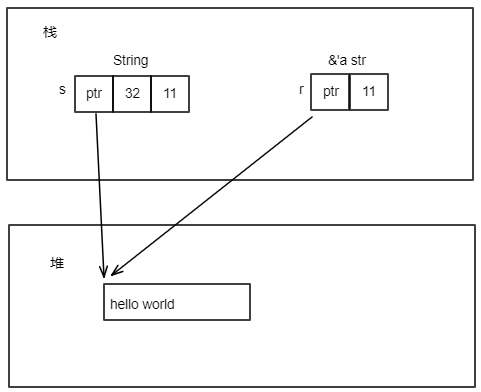
同样的,Vec类型也是一个智能指针。
智能指针通常使用结构体实现,但它不同于普通结构体的地方在于其实现了Deref和Drop trait。Deref trait允许智能指针结构体实例表现的像引用一样;Drop trait则自定义了当智能指针离开作用域时运行的代码。
总结:
- 智能指针是一个胖指针,但胖指针不一定是指针;
- 智能指针拥有对堆上数据的所有权,普通胖指针没有堆上数据的所有权;
- 智能指针实现了
Deref trait和Drop trait,前者用来让智能指针表现的像引用,后者用来实现离开作用域时的代码; - 前面接触过的类型中,
String和Vec类型本质都是智能指针。
3.16.2 Box智能指针
Box智能指针是Rust中最基本的在堆上分配内存的方式。定义Box变量,将值存放在堆上,栈上则保留指向堆数据的指针。除了数据被存储在堆上外,Box没有任何性能损失。
1. Box的基本使用方式
下面为Box使用的简单示例:
fn main() { let b = Box::new(5); //此时5存储在堆上而不是栈上,b本身存储于栈上 println!("b = {}", b); //离开作用域时同时清楚堆和栈上的数据 }
2. 使用Box的内存布局
前面示例中使用Box定义了变量b,其内存布局方式如下:
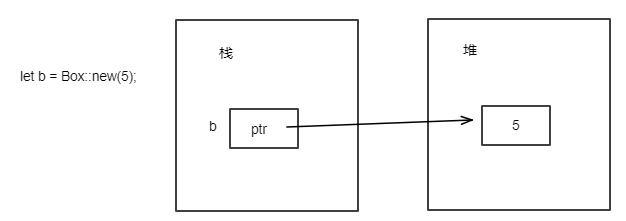
3. Box适合使用的场景
Box适合用于如下场景:
- 当有一个在编译时未知大小的类型,而又需要在确切大小的上下文中使用这个类型值的时候;
- 当有大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候;
- 当希望拥有一个值并只关心它的类型是否实现了特定
trait而不是其具体类型时。
(1)场景1示例:
假定我们需要采用递归的方式定义一个List,其定义可能如下:
// 下面的代码无法编译通过 use crate::List::{Nil, Cons}; enum List { Cons(i32, List),//Cons就类似于c语言的结构体定义: //struct List{ // int data; // struct List next;//编译报错,因为编译器并不知道next有多大,next又是一个List //} Nil, } fn main() { let _list = Cons(1, Cons(2, Cons(3, Nil))); }
但是上面的代码无法编译通过,因为Cons类型在编译时无法确定其具体大小。其内存示意图如下:
此时就需要使用Box,其代码如下:
use crate::List::{Nil, Cons}; enum List { Cons(i32, Box<List>), // 用Box就把它变成了一个指针,Cons就类似于c语言的结构体定义: // struct List{ // int data; // struct List *next; //指向的一个指针,指针的大小是固定的 // } Nil, } fn main() { let _list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil)))))); }
使用Box后,上面的Cons的内存表示如下:
每个Box的大小是固定的,所以编译不会有问题。
(2)场景2示例:
fn main() { let b = Box::new([100u32; 100]); println!("b = {:?}", b); let c = b; // println!("b = {:?}", b); // 此行打开将报错,因为所有权已经转移到c println!("c = {:?}", c); }
(3)场景3示例:
trait Vehicle { fn run(&self); } struct Car(u32); impl Vehicle for Car { fn run(&self) { println!("Car {:?} run ... ", self.0); } } struct Truck(u32); impl Vehicle for Truck { fn run(&self) { println!("Truck {:?} run ... ", self.0); } } //vehicle_run方法的参数要求是一个Vehicle trait对象 fn vehicle_run(vehicle: Box<dyn Vehicle>) { vehicle.run(); } fn main() { let car = Car(1001); let truck = Truck(1002); let v1 = Box::new(car); vehicle_run(v1); let v2 = Box::new(truck); vehicle_run(v2); }
3.16.3 Deref trait
1. 通过*使用引用背后的值
常规引用是一个指针类型,包含了目标数据存储的内存地址。对常规引用使用 * ,可以通过解引用的方式获取到内存地址对应的数据值,示例如下:
fn main() { let x = 5; let y = &x; assert_eq!(5, x); // assert_eq!(5, y); //编译错误,必须通过*才能使用y引用的值 assert_eq!(5, *y); }
2. 通过*使用智能指针背后的值
对于智能指针,也可以通过*使用其背后的值,示例如下:
fn main() { let x = 5; let y = Box::new(x); assert_eq!(5, x); assert_eq!(5, *y); }
3. 使用Deref
实现Deref trait允许我们重载解引用运算符*。通过为类型实现Deref trait,类型可以被当做常规引用来对待。简单来说,如果类型A实现了Deref trait,那么就可以写如下代码:
#![allow(unused)] fn main() { let a: A = A::new(); let b = &a; let c = *b; //对A实现了Deref trait,所以可以对A类型解引用 }
下面的代码定义一个MyBox类型,并为其实现Deref trait:
use std::ops::Deref; struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } impl<T> Deref for MyBox<T> { //为MyBox实现Deref trait type Target = T; fn deref(&self) -> &T { //注意:此处返回值是引用,因为一般并不希望解引用获取MyBox<T>内部值的所有权 &self.0 } } fn main() { let x = 5; let y = MyBox::new(x); assert_eq!(5, x); assert_eq!(5, *y); //实现Deref trait后即可解引用,使用*y实际等价于 *(y.deref()) }
4. 函数和方法的隐式Deref强制转换
对于函数和方法的传参,Rust 提供了隐式转换:Deref 转换。若一个类型实现了 Deref 特征,那它的引用在传给函数或方法时,会根据参数签名来决定是否进行隐式的 Deref 转换,例如:
use std::ops::Deref; struct MyString(String); impl Deref for MyString { // MyString类型实现了Deref trait type Target = str; fn deref(&self) -> &str { self.0.as_str() } } fn print(s: &str) { println!("s: {:?}", s); } fn main() { let y = MyString("Hello".to_string()); print(&y); //此处发生隐式转换,&y从&MyString自动转换为&str类型,转换由&触发,过程如下: // &y隐式转换过程: &MyString -> &str }
上面代码的关键点为:
MyString实现了Deref特征,可以在需要时自动被转换为&str类型;&y是一个&MyString类型,当它被传给print函数时,自动通过Deref转换成了&str;- 必须使用
&y的方式来触发Deref(仅引用类型的实参才会触发自动解引用)。
下面为调用方法时发生的隐式自动转换的例子:
use std::ops::Deref; struct MyType(u32); impl MyType { fn to_u32(&self) -> u32 { self.0 } } struct MyBox(MyType); impl Deref for MyBox { // MyString类型实现了Deref trait type Target = MyType; fn deref(&self) -> &MyType { &self.0 } } fn main() { let mb = MyBox(MyType(5u32)); let _a = mb.to_u32(); // 此行发生隐式转换,转换过程分析如下: // let _a = mb.to_u32() 等价于 let _a = MyType::to_u32(&mb) // MyType::to_u32(&mb)中, // 1、由&触发隐式转换, &mb从&MyBox转换到&MyType // 2、调用MyType的to_u32方法 }
Deref还支持连续的隐式转换,示例如下:
fn print(s: &str) { println!("{}", s); } fn main() { let s = Box::new(String::from("hello world")); print(&s) // &s隐式转换过程:&Box -> &String -> &str }
上面的代码中,Box、String都实现了Deref,当把&s传入到print函数时,发送连续隐式转换(&s先从&Box转换到&String,再转换到&str)。
5. Deref强制转换与可变性交互
类似于如何使用Deref trait 重载不可变引用的运算符,Rust提供了DerefMut trait用于重载可变引用的运算符。
Rust在发现类型和 trait 实现满足三种情况时会进行 Deref 强制转换:
- 当
T: Deref<Target=U>时从&T到&U。 - 当
T: DerefMut<Target=U>时从&mut T到&mut U。 - 当
T: Deref<Target=U>时从&mut T到&U。
3.16.4 Drop trait
1. Drop trait
Drop trait类似于其它语言中的析构函数,当值离开作用域时执行此函数的代码。可以为任何类型提供Drop trait的实现。
为一个类型实现Drop trait的示例如下:
struct Dog(String); //下面为Dog实现Drop trait impl Drop for Dog { fn drop(&mut self) { println!("Dog leave"); } } fn main() { let _a = Dog(String::from("wangcai")); let _b = Dog(String::from("dahuang")); }
运行该代码,会有如下结果:

在上面示例代码中并没有打印语句,但是在drop方法中实现了打印,可以看到,当_a和_b离开作用域时,自动调用了drop方法。
2. 通过std::mem::drop提早丢弃值
当要显示的清理值时,不能直接调用Drop trait里面的drop方法,而要使用std::mem::drop方法,示例如下:
struct Dog(String); //下面为Dog实现Drop trait impl Drop for Dog { fn drop(&mut self) { println!("Dog leave"); } } fn main() { let _a = Dog(String::from("wangcai")); let _b = Dog(String::from("dahuang")); //a.drop();//错误,不能直接调用drop drop(_a); //正确,通过std::mem::drop显示清理 println!("At the end of main"); }
代码运行结果如下:

第一个“Dog leave”打印是第14行调用释放_a产生,最后一个“Dog leave”打印则是_b离开作用域时调用drop方法产生。
3.16.5 Rc智能指针
1. 使用场景分析
假定有这样一个需求,希望创建两个共享第三个列表所有权的列表,其概念类似于如下图:
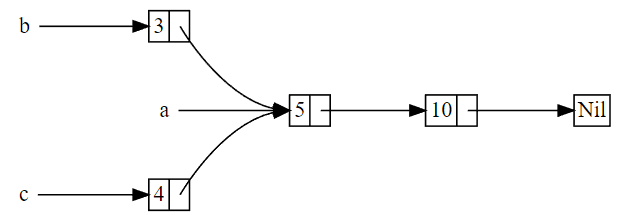
根据前面的知识,可能写出来的代码如下:
enum List { Cons(i32, Box<List>), Nil, } use crate::List::{Cons, Nil}; fn main() { let a = Cons(5, Box::new(Cons(10, Box::new(Nil)))); let b = Cons(3, Box::new(a)); let c = Cons(4, Box::new(a)); }
但是上面的代码报错,因为Rust 所有权机制要求一个值只能有一个所有者。为了解决此类需求,Rust提供了Rc智能指针。
2. 使用Rc共享数据
Rc智能指针通过引用计数解决数据共享的问题,下面是Rc使用的简单代码:
use std::rc::Rc; fn main() { let a = Rc::new(5u32); let b = Rc::clone(&a); let c = a.clone(); }
上面代码中,a、b、c就共享数据5。当创建b时,不会获取a的所有权,会克隆a所包含的Rc(5u32),这会使引用计数从1增加到2并允许a和b共享Rc(5u32)的所有权。
创建c时也会克隆 a,引用计数从2增加为3。每次调用Rc::clone,Rc(5u32)的引用计数都会增加,直到有零个引用之前其数据都不会被清理。其在内存中的表示如下:
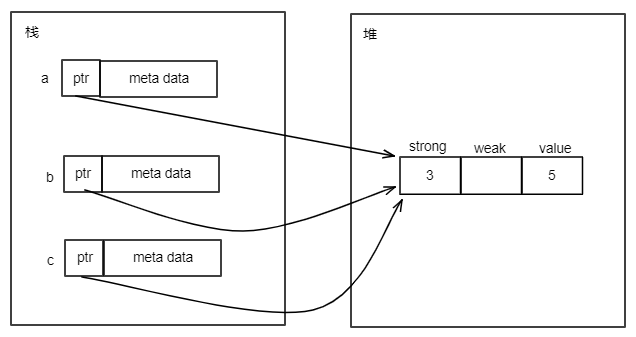
前面共享列表的需求则可以使用Rc实现如下:
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); let b = Cons(3, Rc::clone(&a)); let c = Cons(4, a.clone()); //此处使用a.clone()也是ok的 }
对应的内存示意图如下:
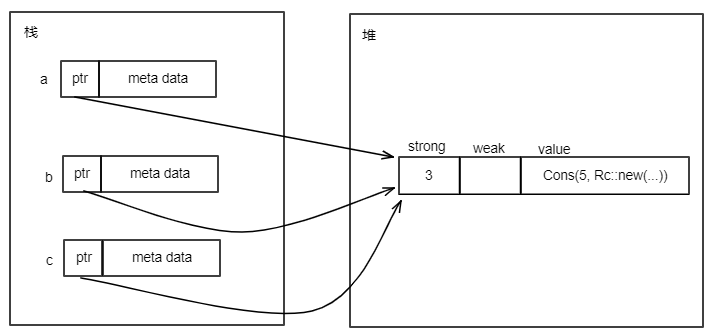
3. 打印Rc的引用计数
下面的示例打印了Rc的引用计数:
enum List { Cons(i32, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::rc::Rc; fn main() { let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil))))); println!("count after creating a = {}", Rc::strong_count(&a)); let _b = Cons(3, Rc::clone(&a)); println!("count after creating b = {}", Rc::strong_count(&a)); { let _c = Cons(4, Rc::clone(&a)); println!("count after creating c = {}", Rc::strong_count(&a)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
使用Rc需要注意以下两点:
- 通过Rc是允许程序的多个部分之间只读的共享数据,因为相同位置的多个可变引用可能会造成数据竞争和不一致。如果涉及到修改,需要使用RefCell或者Mutex。
- Rc只能是同一个线程内部共享数据,它是非线程安全的。如果要在多线程中共享,需要使用Arc。
3.16.6 RefCell智能指针
1. 使用RefCell
内部可变性(Interior mutability) 是Rust中的一个设计模式,它允许在有不可变引用时改变数据,这通常是借用规则所不允许的。RefCell正是为Rust提供内部可变性的智能指针。 在Rust中,当使用mut或者&mut显示的声明一个变量或者引用时,才能修改它们的值。编译器会对此严格检查。
#![allow(unused)] fn main() { let mut a = 1u32; a = 2u32; // 可以修改a的值 let b = 3u32; b = 4u32; // 报错,不允许修改 }
但是当使用RefCell时,可以对其内部包含的内容进行修改,如下:
use std::cell::RefCell; fn main() { let data = RefCell::new(1); // data本身是不可变变量 { let mut v = data.borrow_mut(); *v = 2; // 但是却可以对RefCell内部的值进行修改 } println!("data: {:?}", data.borrow()); // 将输出为2 }
2. 使用RefCell,编译器在运行时检查可变性
在上面的代码中,data本身是一个不可变变量,但是在代码中却可以改变它内部的值(第6行,将值从1改成了2),这就是内部可变性。当使用RefCell定义变量后,编译器会认为:在编译时这个变量是不可变的,但是在运行时可以得到其可变借用,从而改变其内部的值。换句话说,使用RefCell是运行时检查借用规则。
下面是另一个使用RefCell的例子:
#[derive(Debug)] enum List { Cons(Rc<RefCell<i32>>, Rc<List>), Nil, } use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; fn main() { let value = Rc::new(RefCell::new(5)); let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); let b = Cons(Rc::new(RefCell::new(6)), Rc::clone(&a)); //不可变引用 let c = Cons(Rc::new(RefCell::new(10)), Rc::clone(&a)); //不可变引用 *value.borrow_mut() += 10; //得到可变借用,然后修改其内部的值 println!("a after = {:?}", a); println!("b after = {:?}", b); println!("c after = {:?}", c); }
下面是一个使用RefCell时容易犯错的例子:
use std::cell::RefCell; fn main() { let data = RefCell::new(1); // data本身是不可变变量 let mut v = data.borrow_mut(); // 使用可变引用 *v = 2; // 通过可变引用对内部的值进行修改 println!("data: {:?}", data.borrow()); // 编译报错: // 前面使用了可变引用,第7行这里又使用不可变引用,违背所有权规则 }
分析:此处需要注意的是,对于RefCell的可变引用、不可变引用的作用域范围(Rust 1.68.2中),其定义方式还是从定义开始,到花括号前结束。这和普通引用是不一样的,因为在新版编译器中(1.31以后),普通引用的作用域范围变成了从定义开始,到不再使用结束。因此,下面的代码是可以正确的:
fn main() { let mut a = 5u32; let b = &mut a; // b是可变引用 *b = 6u32; // 新版编译器中,b的作用域到这里就结束了 let c = &a; // c是可变引用,因为b的作用域已经结束,所以这里可以使用不可变引用 println!("c === {:?}", c); }
3. 关于Box、Rc或RefCell的选择总结
- Rc允许相同数据有多个所有者;
Box和RefCell有单一所有者。 - Box允许在编译时执行不可变或可变借用检查;Rc仅允许在编译时执行不可变借用检查;RefCell 允许在运行时执行不可变或可变借用检查。
- 因为RefCell允许在运行时执行可变借用检查,所以可以在即便RefCell自身是不可变的情况下修改其内部的值。
3.16.7 引用循环、内存泄露、Weak智能指针
1. 引用循环和内存泄露
下图是一个循环链表:
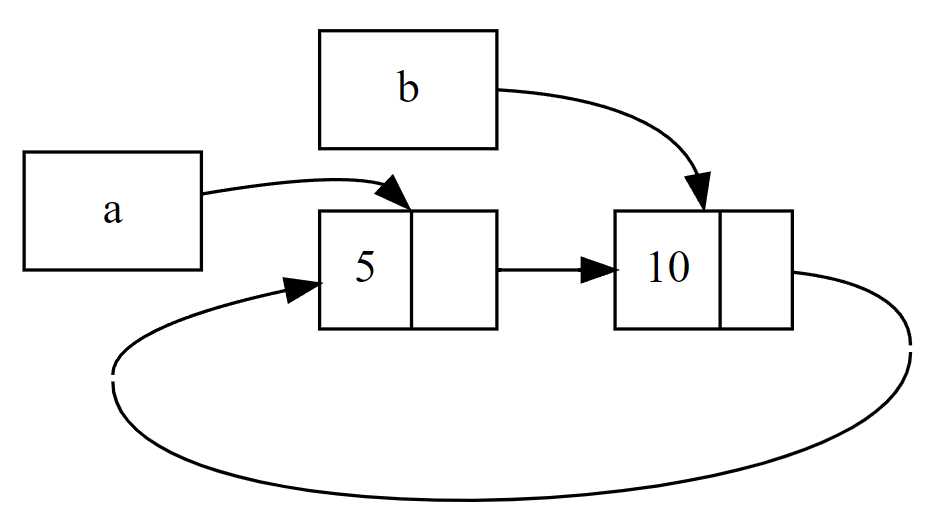
下面的代码试图用之前学到的智能指针相关知识实现上面的链表:
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a initial rc count = {}", Rc::strong_count(&a)); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("a rc count after b creation = {}", Rc::strong_count(&a)); println!("b initial rc count = {}", Rc::strong_count(&b)); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); //将a修改为指向b } println!("b rc count after changing a = {}", Rc::strong_count(&b)); //输出引用计数,为2 println!("a rc count after changing a = {}", Rc::strong_count(&a)); //输出引用计数,为2 //下面的调用将出错,因为上面已经制造了循环引用,编译器无法找到tail // println!("a next item = {:?}", a.tail()); }
下面分析整个过程中的内存布局:
- 当执行完第26行后,内存布局如下:
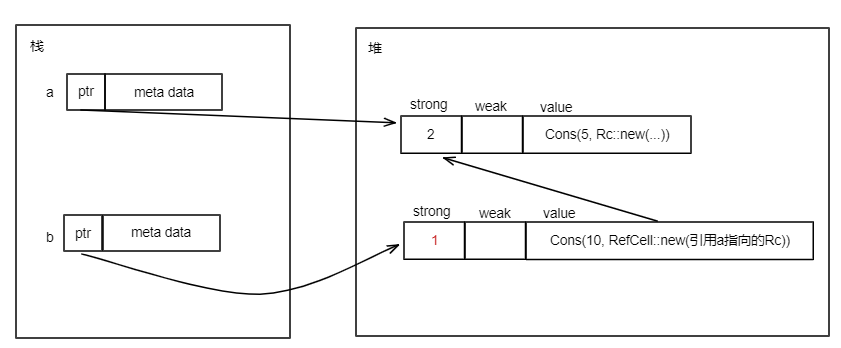
- 在执行完第33行后,b对应的Rc引用计数变成2,内存布局如下:
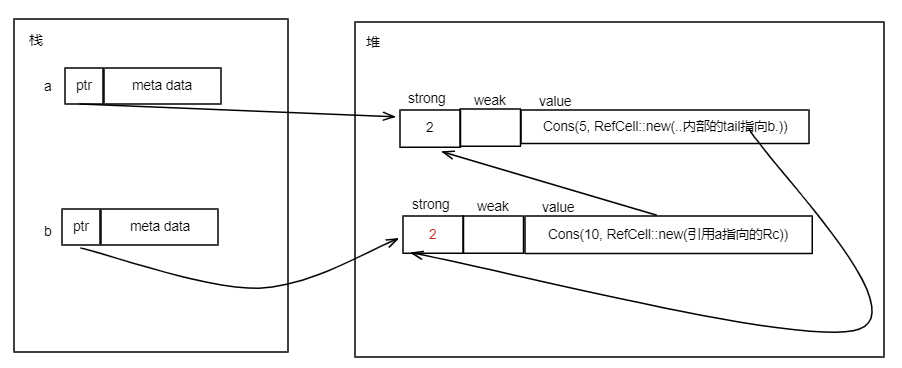
此时如果第40行代码执行将会panic,因为已经成了一个循环链表,Rust无法匹配到a的tail,最终会造成栈溢出。
- 在最后离开作用域时,Rust将会对b和a调用drop方法,对b调用drop方法后,内存布局如下:
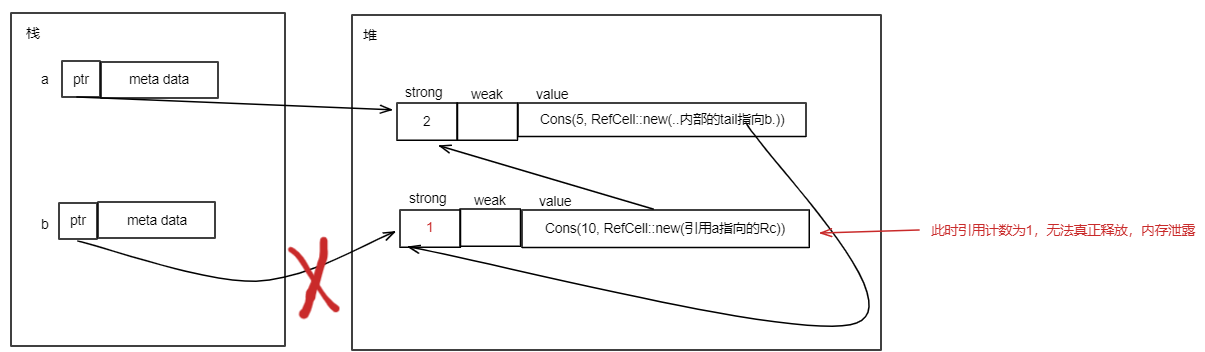
此时b的Rc实例引用计数减去1,但是仍然不为0(因为第33行让a也引用了b的Rc实例),所以b所指向的内存并不会被释放。
- 然后Rust尝试drop a,其对应的Rc示例引用计数减去1,但仍然不为0,所以调用a的drop后,内存布局为:
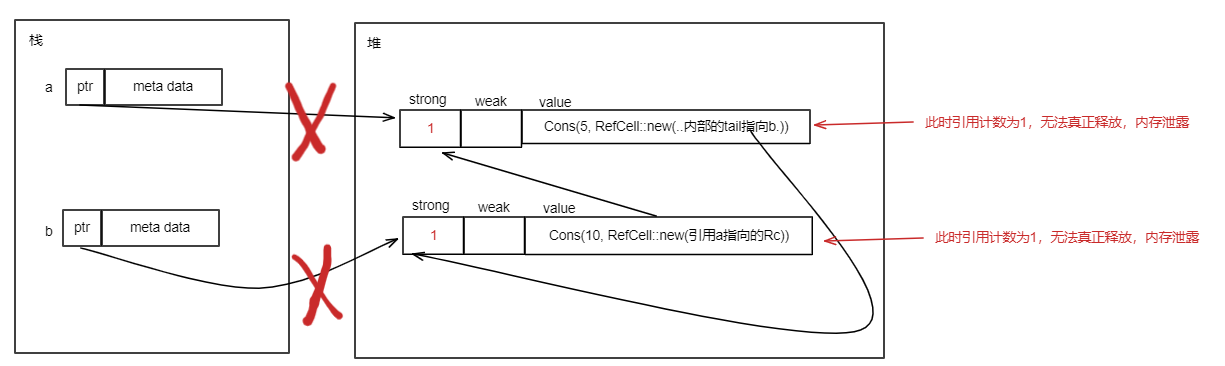
至此,造成内存泄露。
2. 使用弱引用Weak
Weak类似于Rc,但它不持有所有权,它仅仅保存一份指向数据的弱引用。弱引用,就是不保证引用的对象存在,如果不存在,就返回一个 None。
下面为Weak和Rc的对比:
| Weak | Rc |
| ------------------------ | ------------------------ |
| 引用不计数 | 引用计数 |
| 不拥有所有权 | 拥有所有权 |
| 不阻止值被释放 | 阻止值被释放 |
|引用的值存在返回Some,不存在返回None | 引用的值必定存在 |
|通过upgrade取到Option<Rc
对于上一节中循环链表的例子,使用Weak实现为如下:
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; use std::rc::Weak; #[derive(Debug)] enum List { Cons(i32, RefCell<Weak<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Weak<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() { let a = Rc::new(Cons(5, RefCell::new(Weak::new()))); println!( "a initial rc count = {}, weak cnt = {}", Rc::strong_count(&a), Rc::weak_count(&a) ); println!("a next item = {:?}", a.tail()); let b = Rc::new(Cons(10, RefCell::new(Weak::new()))); if let Some(link) = b.tail() { *link.borrow_mut() = Rc::downgrade(&a); } println!( "a rc count after b creation = {}, weak cnt = {}", Rc::strong_count(&a), Rc::weak_count(&a) ); println!( "b initial rc count = {}, weak cnt = {}", Rc::strong_count(&b), Rc::weak_count(&b) ); println!("b next item = {:?}", b.tail()); if let Some(link) = a.tail() { *link.borrow_mut() = Rc::downgrade(&b); } println!( "b rc count after changing a = {}, b weak cnt = {}", Rc::strong_count(&b), Rc::weak_count(&b) ); println!( "a rc count after changing a = {}, a weak cnt = {}", Rc::strong_count(&a), Rc::weak_count(&a) ); // Uncomment the next line to see that we have a cycle; // it will overflow the stack println!("a next item = {:?}", a.tail()); }
下图为上面代码的内存布局示意图:
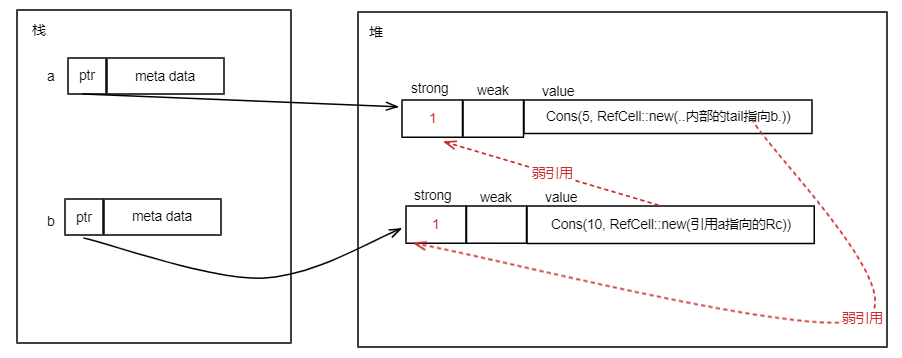
下面再总结一下Weak的特点:
- 可访问,但没有所有权,不增加引用计数,因此不会影响被引用值的释放回收;
- 可由
Rc<T>调用downgrade方法转换成Weak<T>; Weak<T>可使用upgrade方法转换成Option<Rc<T>>,如果资源已经被释放,则Option的值是None;- 常用于解决循环引用的问题。
3.17 包、crate、模块
3.17.1 包、crate和模块介绍
关于三者的描述如下:
- 包(Package)是一个 Cargo 项目,它包含了一个 Cargo.toml 配置文件和一些 Rust 代码文件。一个包可以包含多个 crate,并且可以有多种构建方式和配置。
- crate(Crate)是一个可以编译成库或二进制文件的 Rust 代码单元。每个 crate 都有一个唯一的名称,它可以被其他 crate 引用,也可以被其它包中的代码引用。每个crate都有一个crate root ,它是一个源文件,Rust 编译器以它为起始点来构成crate根模块。对于crate来说,crate root要么是
src/main.rs(对于二进制crate来说),要么是src/lib.rs(对于库crate来说)。 - 模块(Module)是一种组织 Rust 代码的方式,它可以将相关的代码放在一起,形成一个代码块。模块可以嵌套,可以有多个不同的访问级别(public、private),并且可以从其他模块中引用和访问。
三者的范围为:模块< crate < 包,即一个包包含一个或多个crate,一个crate可以包含多个模块。
1. 包含一个crate的包
下面的命令会创建一个Rust工程,这个工程同时是一个crate,也是一个包(只有一个crate的包):
cargo new main
进入main文件夹,其目录层级如下:

其中Cargo.toml的内容如下:

可以看到这个crate的名字为main。
2. 包含多个crate的包
下面再创建一个稍微复杂一点的包。执行如下几条命令:
mkdir my-pack # 创建包文件夹
cd my-pack
cargo new my-lib --lib # 创建一个库crate
cargo new main # 创建一个可执行的二进制crate
然后在my-pack文件夹中添加文件Cargo.toml,其内容如下:
[workspace]
members = [
"main",
"my-lib",
]
最后的目录层级关系如下:
上面的步骤就创建了一个包my-pack,这个包包含两个crate,分别是my-lib和main。
3.17.2 模块 (Module)
1. 使用模块对代码分组
使用模块方便对代码进行分组,以提高可读性和重用性,例如如下代码:
fn main() { println!("Produce something!"); }
将其中的打印代码放入到一个模块中,变成如下:
mod factory { // 创建一个模块 pub fn produce() { // 将打印函数放在模块中 println!("Produce something!"); } } fn main() { factory::produce(); // 调用模块的函数 }
2. 定义模块控制作用域和私有性
使用模块可以控制作用域和私有性,示例如下:
mod factory { pub struct PubStruct { // 该结构体被定义为公有,外部可以使用 pub i: u32, // 该字段被定义为公有,外部可以使用 } struct PrivateStruct { // 该结构体定义为私有,外部无法使用 i: u32, } // 该函数被定义为公有,外部可以使用 pub fn function1() { let p1 = PubStruct { i: 3u32 }; println!("p1 = {:?}", p1.i); let p2 = PrivateStruct { i: 3u32 }; println!("p2 = {:?}", p2.i); function2(); println!("This is a public function!"); } // 该函数被定义为私有,外部无法使用 fn function2() { let p1 = PubStruct { i: 3u32 }; println!("p1 = {:?}", p1.i); let p2 = PrivateStruct { i: 3u32 }; println!("p2 = {:?}", p2.i); println!("This is a private function!"); } } fn main() { let _p1 = factory::PubStruct { i: 3u32 }; // let _p2 = factory::PrivateStruct { i: 3u32 }; // 打开将编译出错,只能访问公有的类型 factory::function1(); // factory::function2(); // 打开编译将出错,只能访问公有的函数 }
模块中的项默认是私有的,要在模块外部使用模块内的一个项,则必须将该项前面加上pub关键字。
3. 绝对路径和相对路径
使用模块中的项时,需要通过对应的路径才能使用这个项。路径有两种形式:
- 绝对路径(absolute path):以 crate root开头的全路径;对于外部 crate 的代码,是以 crate 名开头的绝对路径,对于对于当前 crate 的代码,则以字面值 crate 开头。
- 相对路径(relative path):从当前模块开始,以 self、super 或当前模块的标识符开头。
mod parent { pub struct A(pub u32); pub mod factory { pub fn produce() { let _a1 = super::A(1u32); // 使用相对路径 let _a2 = crate::parent::A(2u32); // 使用绝对路径 println!("Produce something!"); } } } fn main() { crate::parent::factory::produce(); // 使用绝对路径调用模块factory的函数 self::parent::factory::produce(); // 使用相对路径调用模块factory的函数 parent::factory::produce(); // 使用相对路径调用模块factory的函数 }
4. 使用use关键字引入作用域
在外部使用模块中的每个项都带上路径会显得比较重复,可以使用use关键字引入路径,示例如下:
mod parent { pub struct A(pub u32); pub mod factory { pub fn produce() { let _a1 = super::A(1u32); // 使用相对路径 let _a2 = crate::parent::A(2u32); // 使用绝对路径 println!("Produce something!"); } } } mod ss { pub struct B(pub u32); pub fn print() { println!("Hello, world!"); } } fn main() { use parent::factory::produce; // 引入produce的路径,可以直接使用produce produce(); // 直接使用 use ss::*; // 引入路径,可以使用ss中的所有公有的项 let _b = B(8u32); print(); }
还可以使用as关键字为引入的项提供新的名字,示例如下:
pub mod factory { pub fn produce() { println!("Produce something!"); } } fn main() { use factory::produce as new_produce; // 通过as将produce命名为新的名字 new_produce(); // 用新名字使用factory::produce函数 }
5. 将模块拆成多个文件
我们将上面第4点中的第二个例子拆成多个文件,步骤如下:
- 创建一个factory.rs,其内容为mod factory中的内容:
#![allow(unused)] fn main() { // src/factory.rs pub fn produce() { println!("Produce something!"); } }
- 在main.rs中导出mod,如下:
// src/main.rs mod factory; // 导出factory module,module名字和文件名字同名 fn main() { use factory::produce as new_produce; // 通过as将produce命名为新的名字 new_produce(); // 用新名字使用factory::produce函数 }
整个工程的目录结构如下:
3.17.3 再谈crate
1. 创建二进制crate和库crate
可以被编译成可执行文件的crate就是二进制crate,它的代码中必定包含一个main函数。如下方式创建的就是一个二进制crate:
cargo new main
对于库crate的创建,需要加上--lib方式如下:
cargo new my-lib --lib
2. 使用第三方的crate
在Rust项目中,经常会使用第三方的crate。使用第三方的crate主要分为两步:
- 添加依赖;
- 在代码中使用。
下面以使用第三方crate rand为例,来进行演示。
(1)首先创建一个工程:
cargo new main
(2)添加依赖:
cd main
打开main目录下的Cargo.toml文件,在[dependencies]下添加对rand库的依赖(即添加语句rand = "0.8.5"),添加后整个文件的内容如下:
(3)在代码中使用rand库
编写src/main.rs如下:
// src/main.rs use rand::prelude::*; // 引入rand库 fn main() { // 使用rand的函数 let mut rng = rand::thread_rng(); let y: f64 = rng.gen(); println!("y = {:?}", y); }
重点说明:在第二步中,当在Cargo.toml的[dependencies]添加rand = "0.8.5"后,程序编译时,会自动先去拉取rand库相关的内容,拉取完成后进行编译。
3.17.4 工作空间
工作空间 是一系列共享同样的 Cargo.lock 和输出目录的包。使用工作空间,可以将多个crate放在同一个目录下,通过共享依赖来提供更好的代码组织和构建支持。 假定有一个项目my-project,里面包含两个crate,分别是二进制crate main和库crate add,在crate main的代码中使用crate add的功能。下面的示例通过工作空间来组织和管理crate。
1.创建整个工程
命令如下:
mkdir my-project
cd my-project
2.创建crate add
命令如下:
cargo new add --lib
3.编写crate adder的代码
编辑add/src/lib.rs如下:
#![allow(unused)] fn main() { // add/src/lib.rs pub fn add(left: u32, right: u32) -> u32 { left + right } }
4.创建crate main
命令如下:
cargo new main
5.编辑工作空间管理的Cargo.toml
在my-project目录下,创建Cargo.toml,内容如下:
# my-project/Cargo.toml
[workspace]
members = [
"./main",
"./add",
]
6.给crate main添加对crate add的依赖
编辑后的main/src/Cargo.toml如下:
[package]
name = "main"
version = "0.1.0"
edition = "2021"
[dependencies]
add = { path = "../add" } # 添加这行:添加对crate add的依赖
7.在crate main的代码中使用crate add的代码
编辑main/src/lib.rs如下:
// main/src/lib.rs use add::*; fn main() { let ret = add(10u32, 21u32); // 使用crate add的add函数 println!("ret = {:?} !", ret); }
在上面的示例中,通过my-project/Cargo.toml文件管理了main和add两个crate,上面所有步骤完成后,整个项目构成如下:
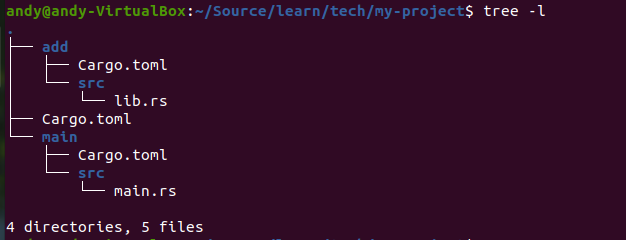
在my-project目录下或者my-project/main目录下运行cargo run可以编译执行整个项目。
3.18 测试
3.18.1 编写测试
1. 测试初体验
测试函数体通常执行如下三种操作:
- 设置需要的数据或者状态;
- 运行需要测试的代码;
- 断言结果是所期望的结果。
Rust提供了专门用来编写测试的功能,即test属性、一些宏和should_panic属性等。 Rust中的测试就是带有一个test属性注解的函数,使用Cargo创建一个新的库时,会自动生成一个测试模块和测试函数,这个模块就是一个编写测试的模板。下面进行演示:
(1)创建一个库
运行如下命令生成一个库:
cargo new adder --lib
(2)查看自动生成的测试模块
打开adder/src/lib.rs可以看到其中内容如下:
#![allow(unused)] fn main() { pub fn add(left: usize, right: usize) -> usize { left + right } //下面为一个测试模块,里面的测试函数it_works对上面的add函数进行测试 #[cfg(test)] mod tests { use super::*; #[test] fn it_works() { // 这是一个测试函数,上面需要加上#[test] let result = add(2, 2); // 调用被测试的函数 assert_eq!(result, 4); // 用断言进行判断结果 } } }
上面的代码演示了如何写测试函数。
(3)运行测试
在adder目录下运行如下命令来执行测试函数:
cargo test
运行后可以看到对应的测试结果:
2. 使用断言
在前面的示例中,测试代码中使用了assert_eq!断言。除了assert_eq!以外,下面几个也是比较常用的断言:
- assert!输入一个布尔值的参数,如果参数为true,断言成功,否则断言失败;
- assert_eq!输入两个参数,两个参数相等,断言成功,否则失败;
- assert_ne!输入两个参数,两个参数不等,断言成功,否则断言失败;
几个断言的使用示例如下:
#![allow(unused)] fn main() { pub fn add(left: usize, right: usize) -> usize { left + right } #[cfg(test)] mod tests { use super::*; #[test] fn it_works() { let result = add(2, 2); assert!(result==4); // 断言成功 assert!(result==2); // 断言将失败 assert_eq!(result, 4); // 断言成功 assert_eq!(result, 2); // 断言失败 assert_ne!(result, 2); // 断言成功 assert_ne!(result, 4); // 断言失败 } } }
3. 使用should_panic!
可以使用should_panic!检查代码是否按照预期panic,示例如下:
#![allow(unused)] fn main() { pub struct Guess { value: i32, } impl Guess { pub fn new(value: i32) -> Guess { if value < 1 || value > 100 { panic!("Guess value must be between 1 and 100, got {}.", value); } Guess { value } } } #[cfg(test)] mod tests { use super::*; #[test] #[should_panic] fn greater_than_100() { Guess::new(200); } } }
4. 使用Result
除了使用断言,还是可以使用Result类型。和断言不同的是,断言写在函数中,而Result类型则是作为测试函数的返回值,示例如下:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { #[test] fn it_works() -> Result<(), String> { // Result类型作为it_works的返回值 if 2 + 2 == 4 { Ok(()) } else { Err(String::from("two plus two does not equal four")) } } } }
3.18.2 运行测试
上一节演示了如何编写测试,对于运行测试则只提到了简单的命令cargo test。本节对执行测试进行详细介绍。
1. 并行或连续运行测试
当运行多个测试时,Rust默认使用线程并行运行。如果不希望测试并行运行,或者更加精确的控制线程的数量,可以传递 --test-threads参数来控制,示例如下:
cargo test -- --test-threads=1 # 使用一个线程运行测试
2. 显示测试中的打印
有的时候,需要在运行测试时打印内容到标准输出,可以添加-- --nocapture或者-- --show-output,例如有如下代码:
#![allow(unused)] fn main() { pub fn add(left: usize, right: usize) -> usize { left + right } #[cfg(test)] mod tests { use super::*; #[test] fn it_works() { let result = add(2, 2); println!("result = {:?}", result); // 打印到标准输出 assert_eq!(result, 4); // 用断言进行判断结果 } } }
要在运行测试时显示12行的打印,可以运行如下命令:
cargo test -- --nocapture
或者
cargo test -- --show-output
3. 运行单个测试
运行测试时,可以通过指定测试函数的名字来运行某个特定的测试函数。例如有如下测试代码:
#![allow(unused)] fn main() { pub fn add_two(a: i32) -> i32 { a + 2 } #[cfg(test)] mod tests { use super::*; #[test] fn add_two_and_two() { assert_eq!(4, add_two(2)); } #[test] fn add_three_and_two() { assert_eq!(5, add_two(3)); } #[test] fn one_hundred() { assert_eq!(102, add_two(100)); } } }
通过指定函数名运行特定的测试函数,下面的命令只会运行函数add_two_and_two:
cargo test add_two_and_two
执行结果如下图:

4. 过滤运行测试
还可以指定部分测试的名称,任何名称匹配这个名称的测试会被运行。例如,因为上面的代码中,前两个测试的名称包含 add,则可以通过 cargo test add 来运行这两个测试:
cargo test add
执行结果如下图:

5. 忽略某个测试
有时候运行cargo test时想忽略其中的某个测试,此时可以通过使用ignore属性来标记该测试来排除它。例如有如下测试代码:
#![allow(unused)] fn main() { pub fn add_two(a: i32) -> i32 { a + 2 } #[cfg(test)] mod tests { use super::*; #[test] #[ignore] //通过添加ignore属性来排除改测试,运行cargo test将不会执行该测试函数 fn add_two_and_two() { assert_eq!(4, add_two(2)); } #[test] fn add_three_and_two() { assert_eq!(5, add_two(3)); } #[test] fn one_hundred() { assert_eq!(102, add_two(100)); } } }
上面的代码中将add_two_and_two用#[ignore]忽略,运行cargo test将不会执行该函数,执行结果如下:
3.19 再谈注释
3.19.1 包和模块级别的注释
包和模块的注释分为两种:行注释 //! 和块注释 /*! ... */ ,这些注释需要添加到文件的最上方。示例如下:
#![allow(unused)] fn main() { /*! 这是一个crate,里面有mod add,此处用的是块注释 */ //! 此处再使用一下行注释 mod add; pub mod sub; }
运行cargo doc --open出现如下界面:
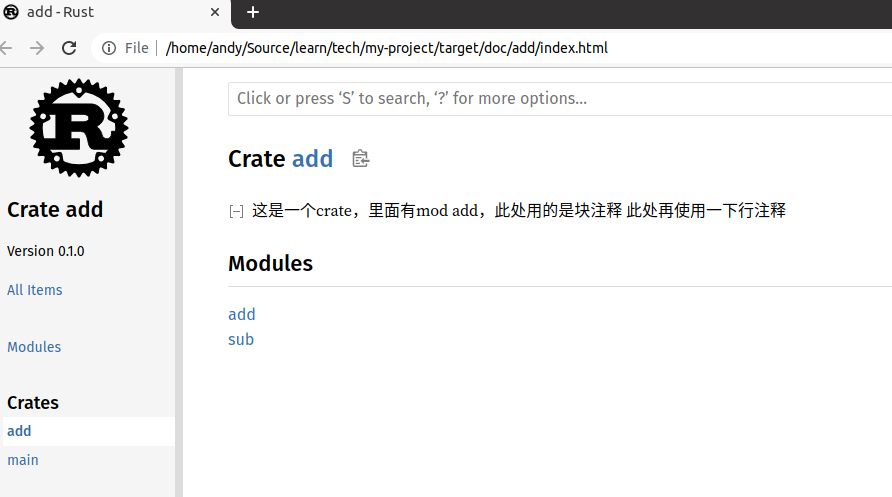
而下面的示例因为没有将所有的包注释放在文件最上面,所以会报错:
#![allow(unused)] fn main() { /*! 这是一个crate,里面有mod add,此处用的是块注释 */ pub mod add; //! 这是一个mod sub,此处用的是行注释,这行将报错,因为必须放置到文件的最上方 pub mod sub; }
3.19.2 文档测试
1. 文档测试
Rust运行在文档注释中写测试用例,示例如下:
#![allow(unused)] fn main() { /// `add` 将两个值相加 /// /// 下面是测试用例 /// ``` /// let ret= add::add::add(5u32, 6u32); /// /// assert_eq!(11u32, ret); /// ``` pub fn add(left: u32, right: u32) -> u32 { left + right } }
测试用例的内容用一对```包含,上面的代码在运行cargo test时,将会运行注释中的测试用例。
2. 保留测试,隐藏注释
还可以保留文档测试的功能,但是把测试用例的内容在文档中隐藏起来,示例如下:
#![allow(unused)] fn main() { /// `add` 将两个值相加 /// /// 下面是测试用例 /// ``` /// let ret= add::add::add(5u32, 6u32); /// /// assert_eq!(11u32, ret); /// ``` pub fn add(left: u32, right: u32) -> u32 { left + right } /// 下面是测试用例 /// ``` /// # // 使用#开头的行会在文档中被隐藏起来,但是依然会在文档测试中运行 /// # let ret= add::add::add2(5u32, 6u32); /// # assert_eq!(Some(11u32), ret); /// ``` pub fn add2(left: u32, right: u32) -> Option<u32> { Some(left + right) } }
运行cargo test,可以看到运行了用例add::add2,如下:
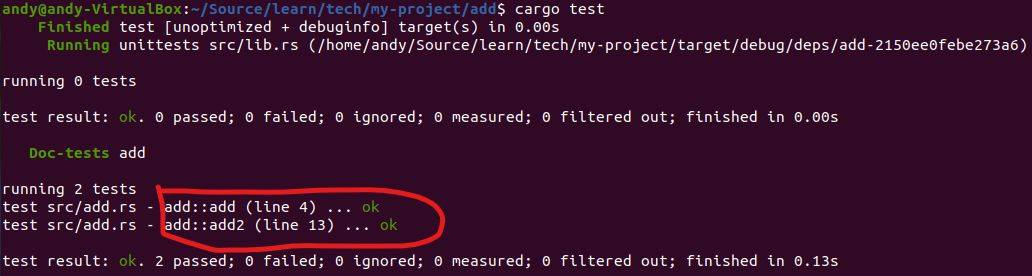
运行cargo doc --open后,打开add和add2的文档,分别如下:
可以看到add2对应的测试用例的内容在文档中被隐藏了。
3.19.3 文档注释中的其它技巧
1. 跳转
Rust文档注释中还可以进行跳转。在文档注释中用[``]包含的内容,可以对其进行跳转,示例如下:
/// `sub` 返回一个[`Option`]类型
/// 跳转到[`crate::add`]
pub fn sub(left: u32, right: u32) -> Option<u32> {
Some(left - right)
}
运行cargo doc --open后,出现如下:
从上图中,点击红色划线部分将分别跳转到标准库的Option和crate::add的位置。
2. 文档搜索别名
可以在Rust文档中为类型定义搜索别名,以便更好的进行搜索,示例如下:
#![allow(unused)] fn main() { #[doc(alias("x"))] pub struct A; }
运行cargo doc --open后,出现如下:
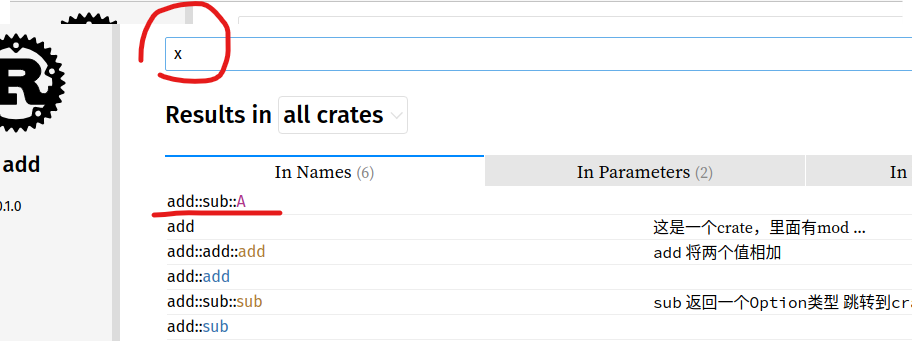
3.20 Rust并发编程
3.20.1 使用线程
3.20.1.1 相关概念
- 进程是资源分配的最小单位,线程是CPU调度的最小单位。
- 在使用多线程时,经常会遇到如下一些问题:
- 竞争状态:多个线程以不一致的顺序访问数据或资源;
- 死锁:两个线程相互等待对方停止使用其所拥有的资源,造成两者都永久等待;
- 只会发生在特定情况下且难以稳定重现和修复的bug。
- 编程语言提供的线程叫做绿色线程,如go语言,在底层实现了M:N的模型,即M个绿色线程对应N个OS线程。但是,Rust标准库只提供1:1的线程模型的实现,即一个Rust线程对应一个Os线程。
3.20.1.2. 创建线程
创建一个新线程需要调用thread::spawn函数并传递一个闭包,示例如下:
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { // 创建一个线程 for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
3.20.1.3. 等待线程结束
前面的例子并不能保证子线程执行完所有的打印,因为主线程有可能在子线程执行完成前结束从而退出程序,所以需要在主线程中等待子线程结束。等待子线程结束需要调用join方法,示例如下:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } handle.join().unwrap(); // 等待子线程结束 }
3.20.1.4. 线程与move闭包
move关键字可用于传递给thread::spawn的闭包,获取环境中的值的所有权,从而达到将值的所有权从一个线程传送到另一个线程的目的。示例如下:
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { // 将v移动进了闭包,完成了值从主线程到子线程的过程 println!("Here's a vector: {:?}", v); }); handle.join().unwrap(); }
3.20.2 传递消息
3.20.2.1. 通道简单介绍
Rust中实现消息传递并发的主要工具是通道。通道由发送者和接受者两部分组成:
- 发送者用来发送消息;
- 接收者用来接收消息;
- 发送者或者接收者任一被丢弃时就认为通道被关闭了。 Rust标准库中提供的通道叫做mpsc,是多个生产者,单个消费者的通道,其使用示例如下:
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); //创建channel,返回发送者、接收者 thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); //使用发送者通过channel发送 }); let received = rx.recv().unwrap(); //使用接收者通过channel接收 println!("Got: {}", received); }
关于mpsc通道的使用,有以下几点说明:
- 发送者的send方法返回一个Result类型,如果接收端已经被丢弃了,将没有发送值的目标,所以发送操作将返回错误;
- 接收者的recv方法也返回Result类型,当通道发送端关闭时,将返回一个错误值表明不会再由新的值到来了;
- 接收还可以使用try_recv方法,recv方法会阻塞到一直等待到消息到来,而try_recv不会阻塞,它会立即返回,Ok值标识包含可用信息,而Err则代表此时没有任何信息。
3.20.2.2. 通道和所有权
在使用通道时,send 函数会获取参数的所有权并移动这个值归接收者所有。例如下面的代码将会编译错误:
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let val = String::from("hi"); tx.send(val).unwrap(); println!("val is {}", val); //错误,此处不能使用val,因为val的所有权已经move到通道里面去了 }); let received = rx.recv().unwrap(); println!("Got: {}", received); }
3.20.2.3. 发送多个值示例
利用通道发送多个值的示例如下:
use std::sync::mpsc; use std::thread; use std::time::Duration; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("thread"), ]; for val in vals { tx.send(val).unwrap(); thread::sleep(Duration::from_secs(1)); } }); for received in rx { println!("Got: {}", received); } }
3.20.2.4. 多个生产者示例
mpsc是multiple producer, single consumer的缩写,此通道可以有多个生产者。相对应的,spmc通道则可以有单个生产者,多个消费者。下面的示例演示多个生产者、单个消费者一起工作:
use std::sync::mpsc; use std::thread; use std::time::Duration; fn main() { let (tx, rx) = mpsc::channel(); let tx1 = mpsc::Sender::clone(&tx); //通过clone来使用 thread::spawn(move || { //第一个发送者线程 let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("thread"), ]; for val in vals { tx1.send(val).unwrap(); thread::sleep(Duration::from_secs(1)); } }); thread::spawn(move || { //第二个发送者线程 let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("thread"), ]; for val in vals { tx.send(val).unwrap(); thread::sleep(Duration::from_secs(1)); } }); for received in rx { println!("Got: {}", received); } }
上面代码中,有两个发送者发送数据,一个接收者结束数据。
3.20.3 共享内存
某些情况下,多个线程之间需要共享内存,即多个线程都访问某个变量。如何在多个线程间安全的共享内存,就需要用到锁、原子操作等机制,下面主要介绍Rust中锁的使用。
3.20.3.1. 互斥锁(Mutex)
在任意时刻,互斥锁只允许一个线程访问数据;在使用数据前需获取锁,使用完成后需要释放锁。关于Mutex的用法示例如下:
use std::sync::Mutex; fn main() { let m = Mutex::new(5); { let mut num = m.lock().unwrap(); *num = 6; // 可以对Mutex内部的值进行修改,可见Mutex和RefCell类似,提供内部可变性 } // 离开作用域,Mutex<T>的锁会自动释放 println!("m = {:?}", m); }
Mutex本质上是一个智能指针,lock()返回一个叫做MutexGuard的智能指针,其内部提供了drop方法,所以当MutexGuard离开作用域时会自动释放锁。Mutex获取到锁后,可以对其内部的值进行修改,可见它和RefCell类似,也提供了内部可变性。
3.20.3.2. 多线程与多所有权
有了Mutex之后,能对共享数据进行保护;但是由于Rust的所有权机制,每个值都有且仅有一个所有者。下面的代码将无法通过编译:
use std::sync::Mutex; use std::thread; fn main() { let counter = Mutex::new(0); let mut handles = vec![]; for _ in 0..10 { let handle = thread::spawn(move || { // 不能将counter移到多个线程中 let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
因此要在多个线程间共享内存,还需要有一种机制能让多个线程都能访问Mutex保护的数据。根据本书目前学到的知识,可以想到Rc智能指针。上面的代码使用Rc智能指针后的示例如下:
use std::rc::Rc; use std::sync::Mutex; use std::thread; fn main() { let counter = Rc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Rc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
上面的代码仍将编译错误,因为Rc是非线程安全的,此时需要使用Arc类型。Arc是一个类似于Rc并可以安全的用于并发环境的类型,使用Arc的示例如下:
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); // 使用Arc共享 let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
3.20.3.3. 读写锁
读变量并不会改变变量的状态,互斥锁Mutex每次读写都会加锁,当在有大量读、少量写的场景时使用Mutex就会效率不高,此时可以使用读写锁RwLock,示例如下:
use std::sync::{Arc, RwLock}; use std::thread; fn main() { let shared_data = Arc::new(RwLock::new(vec![1, 2, 3])); // 创建一个共享的 vector 数据 let mut threads = vec![]; // 创建 5 个读线程 for i in 0..5 { let shared_data = shared_data.clone(); threads.push(thread::spawn(move || { // 获取读锁 let shared_data = shared_data.read().unwrap(); println!("Thread {} read data: {:?}", i, *shared_data); })); } // 创建 2 个写线程 for i in 0..2 { let shared_data = shared_data.clone(); threads.push(thread::spawn(move || { // 获取写锁 let mut shared_data = shared_data.write().unwrap(); println!("Thread {} write data", i); shared_data.push(i); // 向 vector 中添加数据 })); } // 等待所有线程完成 for thread in threads { thread.join().unwrap(); } }
3.20.3.4. 小结
关于Mutex和RwLock的选择:
- 追求高并发读取时,使用RwLock,因为Mutex一次只允许一个线程读取;
- 如果要保证写操作的成功性,使用Mutex;
- 不知道哪个合适,统一使用Mutex。
关于Mutex和Arc类型:
- Mutex和RefCell一样具有内部可变性,不过Mutex是线程安全的,而RefCell不是线程安全的;
- Arc和Rc功能类似,但是Arc是线程安全的,而Rc不是线程安全的。
3.20.4 Send trait和Sync trait
3.20.4.1. Send和Sync
Send trait和Sync trait是Rust语言中的两个标记trait(即未定义任何行为,但是可以标记一个类型),其作用如下:
- 实现了Send的类型可以在线程间安全的传递其所有权;
- 实现了Sync的类型可以在线程间通过引用安全的共享。
实现Sync的类型是通过引用在线程间共享的,因此一个类型要在线程间安全的共享,那么它的应用必须能安全的在线程间进行传递。所以可以有结论:若&T满足Send,那么T满足Sync。
3.20.4.2. 实现了Send和Sync的类型
Rust中几乎所有类型都默认实现了Send和Sync。Send和Sync也是可自动派生的trait,因此一个复合类型,如果其内部成员都实现了Send或Sync,那么它就自动实现了Send或Sync。
Rust中绝大多数类型都实现了Send和Sync,但是下面几个是没有实现Send或者Sync的:
- 裸指针既没有实现Send也没有实现Sync,因为它本身就没有任何安全保证的;
- UnsafeCell没有实现Sync,Cell和RefCell也没有实现Sync(但是它们实现了Send);
- Rc既没有实现Send也没有实现Sync。
通常情况下不需要为某个类型手动实现Send和Sync trait,手动实现这些标记trait 涉及到编写不安全的Rust代码,本书在后面unsafe编程部分介绍。
3.21 unsafe编程
3.21.1 unsafe简介
到此节之前本书介绍的基本都是安全的Rust,即Rust编译时会强制执行内存安全保证的检查,只要编译通过,基本就能保证代码的安全性。既然有安全的Rust,那么必然也有不安全的Rust。
3.21.1.1 不安全的Rust存在的原因
- 代码静态分析相对保守,这就意味着某些代码可能是合法的,但是编译器检查也会拒绝通过。在此情况下,可以使用不安全的代码。
- 底层计算机硬件固有的不安全性。如果Rust不允许进行不安全的操作,有些任务根本就完成不了。
3.21.1.2. 不安全的Rust使用的场景
Rust通过unsafe关键字切换到不安全的Rust,不安全的Rust使用的场景如下:
- 解引用裸指针;
- 调用不安全的函数或者方法;
- 访问或修改可变静态变量;
- 实现不安全的trait。
注意:unsafe并不会关闭借用检查器或禁用任何其它的Rust安全检查规则,它只提供上述几个不被编译器检查内存安全的功能。unsafe也不意味着块中的代码一定是有问题的,它只是表示由程序员来确保安全。
3.21.2 使用unsafe编程
3.21.2.1. 解引用裸指针
裸指针又称为原生指针,在功能上和引用类似,但是引用的安全由Rust编译器保证,裸指针则不是。裸指针需要显式标明可变性,不可变的裸指针分别写作 *const T ,可变的裸指针写作 *mut T。
裸指针与引用和智能指针的区别如下:
- 可以忽略借用规则,在代码中同时拥有不可变和可变的裸指针,或多个指向相同位置的可变裸指针;
- 不保证裸指针指向有效的内存;
- 允许裸指针为空;
- 裸指针不能实现任何自动清理功能。
可以在安全代码中创建可变或不可变的裸指针,但是只能在不安全块中解引用裸指针,示例如下:
fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; let address = 0x012345usize; let _r = address as *const i32; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } }
说明:创建一个裸指针不会造成任何危险,只有当访问其指向的值时(并且这个值已经无效)才可能造成危险,所以可以在安全的代码块中创建裸指针,但是使用则必须在unsafe的块中。
3.21.2.2. 调用不安全的函数或者方法
示例1,代码如下:
unsafe fn dangerous() { println!("Do some dangerous thing"); } fn main() { unsafe { dangerous(); } println!("Hello, world!"); }
示例2,代码如下:
fn foo() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; unsafe { println!("r1 is: {}", *r1); println!("r2 is: {}", *r2); } } fn main() { foo(); }
3.21.2.3. 访问或者修改可变静态变量
全局变量在Rust中被称为静态变量。静态变量的名称采用SCREAMING_SNAKE_CASE写法,它只能存储拥有 'static生命周期的引用。下面的示例使用了不可变的静态变量:
static HELLO_WORLD: &str = "Hello, world!"; // 不可变的静态变量 fn main() { println!("name is: {}", HELLO_WORLD); }
这里对比一下常量和静态变量:
- 静态变量中的值有一个固定的内存地址(即使用这个值总会访问相同的地址),常量则允许在任何被用到的时候复制其数据。
- 静态变量可以是可变的,虽然这可能是不安全的。
下面的示例使用可变的静态变量:
static mut COUNTER: u32 = 0; // 可变的静态变量,同样需要mut关键字 fn add_to_count(inc: u32) { unsafe { COUNTER += inc; } } fn main() { add_to_count(3); unsafe { println!("COUNTER: {}", COUNTER); } }
3.21.2.4. 实现不安全的trait
当至少有一个方法中包含编译器不能验证的invariant时,该trait就是不安全的。在trait之前增加unsafe关键字将trait声明为unsafe,同时trait的实现也必须标记为unsafe。下面为使用unsafe的trait的示例:
struct Bar; unsafe trait Foo { fn foo(&self); } unsafe impl Foo for Bar { fn foo(&self) { println!("foo"); } } fn main() { let a = Bar; a.foo(); }
3.22 FFI介绍
3.22.1 在Rust中调用C
1. 构建脚本build.rs
- 构建脚本build.rs简单使用
build.rs中可以进行真正的项目代码编译前需要的额外的工作,例如在编译前为项目生成对应的文件、代码,编译所依赖的外部语言库等。build.rs放置在正式代码的外面(也就是src的外面)。 下面示例在build.rs中生成一个文件,然后在正式的项目代码中读取这个文件,build.rs中的代码如下:
// build.rs use std::fs; fn main() -> std::io::Result<()> { fs::write("foo.txt", b"Lorem ipsum")?; // 在build.rs生成文件foo.txt,并写入字符串 Ok(()) }
src/main.rs中的代码如下:
// src/main.rs use std::fs; fn main() { let s = fs::read_to_string("./foo.txt").expect("Read file error"); // 读取foo.txt文件 println!("s = {:?}", s); }
运行前整个项目的目录结构如下:
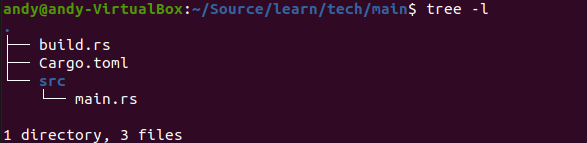
运行cargo run执行程序结果如下:

运行后整个项目的目录结构如下:
- 构建脚本的生命周期
在项目构建之前,Cargo会将build.rs编译成可执行文件,然后执行。在执行过程中,脚本可以使用println的方式跟Cargo进行通信,通信内容的格式为:cargo:真正的内容。
示例如下:
// build.rs fn main() { println!("cargo:rustc-link-search=/usr/local/lib/"); println!("cargo:rustc-link-lib=dylib=pcre2-8"); println!("cargo:rerun-if-changed=src/lib.rs"); }
- 构建脚本的输入
可以通过环境变量、文件等方式给构建脚本提供一些输入。
- 构建脚本的输出
如果构建脚本生成文件,可以指定该文件的输入目录,可以通过设置OUT_DIR环境变量来指定。构建脚本的输出通常是用来告诉Cargo一些信息,以下几个为常用的Cargo能识别的通信指令:
-
cargo:rerun-if-changed=PATH — 当指定路径的文件发生变化时,Cargo会重新运行脚本;
-
cargo:rerun-if-env-changed=VAR — 当指定的环境变量发生变化时,Cargo会重新运行脚本;
-
cargo:rustc-link-lib=[KIND=]NAME — 告诉Cargo通过-l去链接一个指定的库,常用于FFI;
-
cargo:rustc-link-search=[KIND=]PATH — 告诉Cargo通过-L将一个目录添加到依赖库搜索路径中;
-
cargo:rustc-env=VAR=VALUE — 设置一个环境变量。
-
构建脚本的依赖
构建脚本也可以引入其它基于Cargo的依赖包,依赖方式为在Cargo.toml中添加依赖包,示例如下:
# Cargo.toml
...
[build-dependencies]
cc = "1.0.46" # 可以在build.rs中使用cc相关的功能
可以看到有一个foo.txt文件,该文件就是在build.rs中生成的。
2. 在Rust中调用C代码
在Rust中调用c的代码需要使用extern关键字来定义外部函数接口,即用extern块把c提供的函数接口进行封装。
下面的示例展示如何在Rust中使用c代码,整个项目的目录结构如下:
c目录中的pass.c为c代码,源码如下:
// c/pass.c
#include <stdio.h>
void set_err(char *message) { // 提供一个打印错误信息的函数
printf("err: %s\n", message);
}
src目录中为Rust代码,源码如下:
// ==================
// 封装c函数
extern "C" { // 在Rust中调用c的代码需要使用extern关键字,定义外部函数接口,
// 实际上就是: 用extern块将c提供的函数接口封装下
fn set_err(message: *const libc::c_char);
}
// ==================
fn main() {
let err = "some error".to_string();
let c_err = std::ffi::CString::new(err).expect("error");
unsafe { // 需要unsafe块
set_err(c_err.as_ptr()); // 调用封装的c函数
}
}
build.rs中的内容如下:
// build.rs fn main() { // 以下代码告诉 Cargo ,`c/pass.c`发生改变,就重新运行当前的构建脚本 println!("cargo:rerun-if-changed=src/hello.c"); // 使用 `cc` 来构建一个 C 文件,然后进行静态链接 cc::Build::new() .file("c/pass.c") .compile("pass"); }
Cargo.toml中的内容如下:
[package]
name = "use-c"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[build-dependencies]
cc = "1.0.46" # build.rs中依赖cc,所以此处需要添加
[dependencies]
libc = "0.2.139" # src/main.rs中使用了libc这个库
可以使用cargo run对这个工程编译运行。
3.22.2 在C中调用Rust
在c中调用Rust,需要把Rust的实现进行封装,封装时主要做以下四点:
- 提供Rust方法、trait方法等公开接口的独立函数。对于泛型函数,需要提供具体某个类型的函数。
- 所有暴露给c的独立函数都要声明成#[no_mangle]。
- 数据结构要转换成和c兼容的结构。如果是自己定义的结构体,需要使用#[repr(c)]。
- 要是用catch_unwind把所有可能产生panic!的代码包裹起来。
下面示例展示在c中调用Rust,其目录结构如下:
目录中的foo是Rust代码,用cargo new foo --lib创建,其中src/lib.rs的代码如下:
#![allow(unused)] #![crate_type = "staticlib"] // 生成静态库 fn main() { #[no_mangle] // 暴露给c的函数要声明#[no_mangle] pub extern fn foo(){ println!("use rust"); } }
foo目录下的Cargo.toml内容如下:
[package]
name = "foo"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
[lib]
name = "foo" # foo编译后对应的库名字
crate-type = ["staticlib"] # 表示编译为静态库
在foo目录下运行命令cargo build编译,在foo/target/debug/目录下会生成静态库libfoo.a。
main.c中的c代码如下:
#include <stdio.h>
extern void foo(); // foo函数为Rust提供的函数
int main()
{
foo();
return 0;
}
在main.c同级目录运行命令gcc -o main main.c ./foo/target/debug/libfoo.a -lpthread -ldl会生成执行文件main,如下图:

3.23 宏介绍
Rust中的宏分为两大类,分别是声明宏和过程宏:
3.23.1 声明宏
声明宏使用macro_rules!定义,是Rust中最常用的宏形式。下面代码中定义Vec时使用的vec!就是一个声明宏:
fn main() { let _v = vec![1, 2, 3]; // 使用声明宏vec!定义一个Vec }
下面的例子演示定义一个声明宏并使用它:
// 定义一个声明宏my_vec macro_rules! my_vec { ( $( $x:expr ),* ) => { { let mut temp_vec = Vec::new(); $( temp_vec.push($x); )* temp_vec } }; } fn main() { let v = my_vec![1, 2, 3]; // 使用声明宏 my_vec! println!("v: = {:?}", v); }
3.23.2 过程宏
过程宏接收Rust代码作为输入,在这些代码上进行操作,然后产生另一些代码作为输出,而非像声明式宏那样匹配对应模式然后以另一部分代码替换当前代码。
过程宏分为三类,分别如下:
- 自定义derive宏,在结构体、枚举等类型上通过#[derive()]指定derive属性添加代码;
- 类属性宏,定义可用于任意项的自定义属性;
- 类函数宏,看起来像函数但是作用于作为参数传递的Token。
1. 自定义derive宏
在本书之前就已经见到过的结构体上的#[derive(Copy, Debug, Clone)]就是自定义derive宏,其功能实际上就是为类型生成对应的代码。例如下面的代码:
#![allow(unused)] fn main() { #[derive(Copy)] struct A { a: u32, } }
对结构体A加上#[derive(Copy)]宏会为结构体A生成实现Copy trait的相关代码。所以使用自定义derive宏实际上涉及到三部分代码,分别是:
- 要生成的目标代码,例如对于#[derive(Copy)]来说,其目标代码实际上就Copy trait的实现代码;
- 为类型生成目标代码的代码;
- 在类型上标注的#[derive(xx属性)]。
下面给出一个完整的自定义derive宏的示例,整个项目的目录如下:
整个项目中有三个crate,功能分别如下:
- my-trait中定义了一个MyTrait trait;
- impl-derive中是为某个类型实现MyTrait trait的代码,提供了MyDeriveMacro宏,当在某个类型上面加上#[derive(MyDeriveMacro)]就会自动为它实现MyTrait;
- main中定义了一个结构体,使用上面的MyDeriveMacro宏。
最外层的Cargo.toml中定义了工作空间,内容如下:
[workspace]
members = [
"./main",
"./impl-derive",
"./my-trait",
]
(1)实现my-trait
- 运行cargo new my-trait --lib创建;
- 编写src/lib.rs代码如下:
#![allow(unused)] fn main() { // my-trait/src/lib.rs pub trait MyTrait{ // 定义MyTrait fn do_something(); } }
(2)实现impl-derive
- 运行cargo new impl-derive --lib创建;
- 在Cargo.toml中添加依赖,如下:
# impl-derive/Cargo.toml
[package]
name = "impl-derive"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
#######################
# 下面的几行为添加的内容
#######################
[lib]
proc-macro = true
[dependencies]
syn = "2.0.15"
quote = "1.0.26"
- 编写src/lib.rs如下:
#![allow(unused)] fn main() { // impl-derive/src/lib.rs extern crate proc_macro; use crate::proc_macro::TokenStream; use quote::quote; use syn; // 为某个类型实现MyTrait fn impl_mytrait(ast: &syn::DeriveInput) -> TokenStream { let name = &ast.ident; let gen = quote! { impl MyTrait for #name { fn do_something() { println!("Do something, my name is {}", stringify!(#name)); } } }; gen.into() } // 把宏和函数对应起来,如果类型上面加了#[derive(MyDeriveMacro)] // 就类似于是为其调用impl_mytrait_derive函数 #[proc_macro_derive(MyDeriveMacro)] pub fn impl_mytrait_derive(input: TokenStream) -> TokenStream { let ast = syn::parse(input).unwrap(); //DeriveInput impl_mytrait(&ast) } }
(3)实现main
- 编写Cargo.toml文件为其添加依赖:
[package]
name = "main"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
my-trait = {path = "../my-trait"} # 添加这行
impl-derive = {path = "../impl-derive"} # 添加这行
- 编写src/lib.rs:
// main/src/lib.rs use my_trait::MyTrait; use impl_derive::MyDeriveMacro; #[derive(MyDeriveMacro)] // 使用MyDeriveMacro宏后,就为Main实现了MyTrait struct Main; fn main() { Main::do_something(); // 因为实现了MyTrait,所以可以调用do_something函数 }
2. 类函数宏
类函数宏是类似于函数那样的过程宏,下面的工程演示类函数宏,其目录结构如下:
(1)定义工作空间
编写最外层的Cargo.toml文件,内容如下:
[workspace]
members = [
"./main",
"./impl-fn-macro",
]
(2)实现impl-fn-macro
- 修改impl-fn-macro/Cargo.toml文件如下:
# impl-fn-macro/Cargo.toml文件
...
[lib] # 添加这行
proc-macro = true # 添加这行
- 编写impl-fn-macro/src/lib.rs如下:
#![allow(unused)] fn main() { // impl-fn-macro/src/lib.rs use proc_macro::TokenStream; #[proc_macro] pub fn make_answer(_item: TokenStream) -> TokenStream { "fn answer() -> u32 { 42 }".parse().unwrap() // 生成answer函数 } }
(3)实现main
- 添加main需要的依赖,修改main/Cargo.toml如下:
# main/Cargo.toml文件
[dependencies]
impl-fn-macro = {path = "../impl-fn-macro"} # 添加这行
- 编写main/src/main.rs代码如下:
// main/src/main.rs use impl_fn_macro::make_answer; make_answer!(); // 调用函数宏生成answer函数 fn main() { println!("{}", answer()); }
3. 类属性宏
属性宏和自定义derive宏类似,不同的是derive宏生成代码,而类属性宏可以创建新的属性。自定义derive宏只能用于结构体和枚举,属性宏则还可以用于其它的项,如函数。下面的工程演示类属性宏,其目录结构如下:
(1)定义工作空间
编写最外层的Cargo.toml文件,内容如下:
[workspace]
members = [
"./main",
"./impl-attr-macro",
]
(2)实现impl-attr-macro
impl-attr-macro中实现了类属性宏func_info。
- 修改impl-attr-macro/Cargo.toml文件如下:
# impl-attr-macro/Cargo.toml文件
...
## 添加下面2行
[lib]
proc_macro = true
[dependencies]
## 添加下面3行
syn = { version = "2.0.15", features = ["parsing", "extra-traits","full", "visit"] }
quote = "1.0.26"
proc-macro2 = "1.0.56"
- 编辑impl-attr-macro/src/lib.rs文件如下:
#![allow(unused)] fn main() { use proc_macro::TokenStream; use quote::quote; use syn::{parse_macro_input, ItemFn}; // 定义属性宏,属性宏的名字就叫做func_info #[proc_macro_attribute] pub fn func_info(_: TokenStream, input: TokenStream) -> TokenStream { let mut func = parse_macro_input!(input as ItemFn); let func_name = &func.sig.ident; let func_block = &func.block; let output = quote! { { println!("fun {} starts", stringify!(#func_name)); let __log_result = { #func_block }; println!("fun {} ends", stringify!(#func_name)); __log_result } }; func.block = syn::parse2(output).unwrap(); quote! { #func }.into() } }
(3)实现main
- 添加main需要的依赖,修改main/Cargo.toml如下:
# main/Cargo.toml文件
[dependencies]
impl-attr-macro = {path = "../impl-attr-macro"} # 添加这行
- 编写main/src/main.rs代码如下:
// main/src/main.rs use impl_attr_macro::func_info; #[func_info] // 为foo函数添加属性宏 fn foo() { println!("Hello, world!"); } fn main() { foo(); // 会自动加上属性宏中的内容 }
4.1. Rust代码风格与格式化
4.1.1 Rust官方的编码风格
遵循Rust官方编码风格有助于提高代码的可读性和可维护性。以下为一些关键的Rust编码风格规范:
-
命名规范
- 变量名和函数名:使用小写字母和下划线的蛇形命名法(snake_case),如
variable_name和function_name。 - 类型名(包括结构体、枚举和类型别名):使用大驼峰式命名法(UpperCamelCase),如 TypeName。
- 常量名:使用大写字母和下划线的蛇形命名法(SCREAMING_SNAKE_CASE),如
CONSTANT_NAME。 - 生命周期参数名:使用小写字母和撇号(tick),如
'a。
- 变量名和函数名:使用小写字母和下划线的蛇形命名法(snake_case),如
-
代码布局
- 缩进:使用 4 个空格而非制表符(tab)进行缩进。
- 空行:在函数和模块之间使用空行进行分隔。
- 括号和操作符:在括号和操作符两侧使用空格进行分隔,例如
let x = a + b;。 - 逗号:在逗号后面使用空格,如
fn example(a: i32, b: String) { ... }。 - 最大行宽:建议将每行代码的长度限制在 100 个字符以内。在某些情况下,可以适当增加到 120 个字符。
-
注释:
- 单行注释:使用 // 进行单行注释,注释文字与 // 之间留一个空格。
- 多行注释:使用
/* */进行多行注释。将注释内容与 /* 和 */ 之间分隔一个空格。
-
文档注释:
- 单行文档注释:使用
///进行单行文档注释,注释文字与///之间留一个空格。 - 多行文档注释:使用
/** */进行多行文档注释。将注释内容与/**和*/之间分隔一个空格。
- 单行文档注释:使用
-
模块和包导入:
- 模块导入:将导入语句放在文件顶部,按字母顺序排序,使用空行分隔不同来源的导入。
- 尽量使用绝对导入路径:在导入路径前添加
crate::或self::。
-
错误处理:
- 使用
Result类型进行错误处理,避免使用panic!和unwrap()。 - 使用
?运算符进行错误传递。
- 使用
4.1.2 使用rustfmt进行自动格式化
-
安装rustfmt
安装rustfmt的命令如下:
rustup component add rustfmt安装rustfmt命令后,可以执行Cargo fmt或者rustfmt 文件名进行格式化。
-
配置rustfmt
可以为项目添加一个rustfmt的配置,添加方式如下:
- 在项目根目录下创建一个名为rustfmt.toml的文件,此文件将包含所有rustfmt的配置选项。
- 下面为比较常见的rustfmt.toml配置:
max_width = 100 // 设置最大行宽为 100 个字符 tab_spaces = 4 // 设置缩进宽度为 4 个空格 edition = "2018" // 设置 Rust 版本(根据实际项目版本进行调整) use_small_heuristics = "Max" // 设置换行策略 newline_style = "Auto" // 设置换行符风格,根据平台自动选择 - 更多配置选项可以在 官方文档 中找到。
-
使用rustfmt格式化代码
- 对整个目录中的所有rust代码格式化,需在项目根目录下运行如下命令:
cargo fmt - 如果只对某个文件进行格式化,则运行如下命令:
rustfmt src/lib.rs - 如果只想检查代码格式是否符合规范,而不进行实际格式化操作,则可以运行如下命令:
cargo fmt -- --check
- 对整个目录中的所有rust代码格式化,需在项目根目录下运行如下命令:
4.2. 使用 Clippy 进行代码静态检查
Clippy是用于捕获常见错误和改进Rust代码的lint集合,下面介绍其安装和使用。
4.2.1. 安装与配置Clippy
安装clippy的命令如下:
rustup component add clippy
安装完成后,可以使用cargo clippy命令来运行Clippy对Rust代码进行静态检查。
4.2.2 配置Clippy
在项目根目录下创建一个名为.clippy.toml的文件,此文件中包含所有Clippy的配置选项。以下是一些常用的clippy配置选项:
# 允许 main 函数有未使用的变量
allow_unused_variables_in_main = true
# 禁用特定 lint
warn_about_specific_lints = ["clippy::unwrap_used"]
4.2.2. Clippy 的基本用法
-
运行Clippy 在项目根目录下,使用以下命令运行Clippy对整个项目进行静态检查:
cargo clippy
执行命令后,Clippy会报告可能的代码问题、不符合 Rust 惯例的编程方式以及潜在的错误。
-
运行Clippy检查特定目标 如果只想针对特定目标(如库、二进制文件或测试)运行Clippy,可以使用--bin、--lib或--test选项。例如,检查名为my_binary的二进制目标:
cargo clippy --bin my_binary -
控制Clippy的警告级别
-
默认情况下,Clippy会将检查到的问题作为警告报告。可以通过添加
#![deny(clippy::all)]或#![deny(clippy::pedantic)]到项目的main.rs或lib.rs文件中,将Clippy的警告级别提升为错误。#![deny(clippy::all)] // 启用所有 Clippy 检查,将警告级别提升为错误 -
要启用更多的 lint,可以使用 `clippy::pedantic:
#![deny(clippy::pedantic)] // 启用所有 pedantic 检查,将警告级别提升为错误
- 禁用特定的 Clippy 检查
-
如果想要禁用特定的Clippy检查,可以在.clippy.toml文件中设置。下面的命令禁用
clippy::unwrap_used检查:warn_about_specific_lints = ["clippy::unwrap_used"] -
也可以在代码中使用属性来禁用某个检查:
#[allow(clippy::unwrap_used)] fn main() { let maybe_number: Option<i32> = Some(42); let number = maybe_number.unwrap(); // Clippy 不会报告这里使用了 unwrap }
4.2.3. 解决 Clippy 指出的问题
当Clippy指出代码中存在问题时,需要对这些问题进行分析并采取相应的解决措施。以下是一些常见问题的解决方法:
-
不安全的
unwrap()使用:- 问题:使用
unwrap()从Option或Result类型中提取值时,如果值为None或Err,程序将panic。 - 解决方法:使用
match语句或if let语句处理None或Err的情况,或使用unwrap_or、unwrap_or_else、unwrap_or_default等方法提供默认值或替代方案。
- 问题:使用
-
不必要的 clone() 调用:
- 问题:在不需要的情况下调用
clone(),可能导致性能下降。 - 解决方法:审查代码,确保只在需要复制数据时才使用
clone()。在其他情况下,考虑使用引用或借用。
- 问题:在不需要的情况下调用
-
使用
expect()代替unwrap():- 问题:使用
unwrap()时,如果发生panic,错误信息可能不够清晰。 - 解决方法:使用
expect()提供自定义的错误信息,使错误更容易诊断。
- 问题:使用
-
使用
if let代替match:- 问题:当
match语句仅包含一个分支时,使用if let可以简化代码。 - 解决方法:将单分支的 match 语句替换为
if let语句。
- 问题:当
-
优先使用迭代器方法:
- 问题:手动编写循环时,可能导致低效或不清晰的代码。
- 解决方法:使用迭代器方法(如
map、filter、fold等)来简化循环和集合操作。
-
避免
Box中的引用:- 问题:在
Box中存储引用可能导致不必要的间接寻址和潜在的性能损失。 - 解决方法:审查代码,直接使用
Box存储值,或考虑使用其他智能指针(如Rc或Arc)。
- 问题:在
-
使用
lazy_static宏进行静态变量初始化:- 问题:在运行时初始化静态变量可能导致性能损失。
- 解决方法:使用
lazy_static宏按需初始化静态变量,以提高性能。
-
避免不必要的
mut关键字:- 问题:使用
mut关键字声明可变绑定,但实际上没有进行任何修改。 - 解决方法:删除不必要的
mut关键字,以提高代码的可读性和安全性。
- 问题:使用
-
使用
const而非static:- 问题:对于不可变的全局变量,使用
static关键字可能会导致不必要的间接寻址。 - 解决方法:将
static替换为const以消除间接寻址,提高性能。
- 问题:对于不可变的全局变量,使用
-
使用
derive自动生成实现:- 问题:手动实现某些
trait(如Debug、PartialEq等)可能会导致不必要的冗余代码。 - 解决方法:使用
#[derive()]属性让 Rust 自动生成这些trait的实现。
- 问题:手动实现某些
-
使用
Default trait提供默认值:- 问题:为类型提供默认值时,使用手动实现的
new函数可能不够清晰。 - 解决方法:为类型实现
Default trait,并使用default()方法提供默认值。
- 问题:为类型提供默认值时,使用手动实现的
-
避免不必要的类型转换:
- 问题:进行不必要的类型转换可能导致性能损失。
- 解决方法:审查代码,确保仅在必要时进行类型转换。如果可以避免类型转换,请直接使用正确的类型。
-
使用
?运算符简化错误处理:- 问题:使用
match语句处理Result类型可能导致冗长的代码。 - 解决方法:使用
?运算符简化错误处理,将错误向上层函数传递。
- 问题:使用
-
使用 cargo fix 自动修复某些问题:
- 问题:手动修复 Clippy 指出的问题可能耗时较长。
- 解决方法:尝试使用 cargo fix 命令自动修复某些 Clippy 指出的问题。但是cargo fix可能无法解决所有问题,仍然需要手动审查和修复部分问题。